Abstract
We propose a novel visual tracking algorithm based on the representations from a discriminatively trained Convolutional Neural Network (CNN).
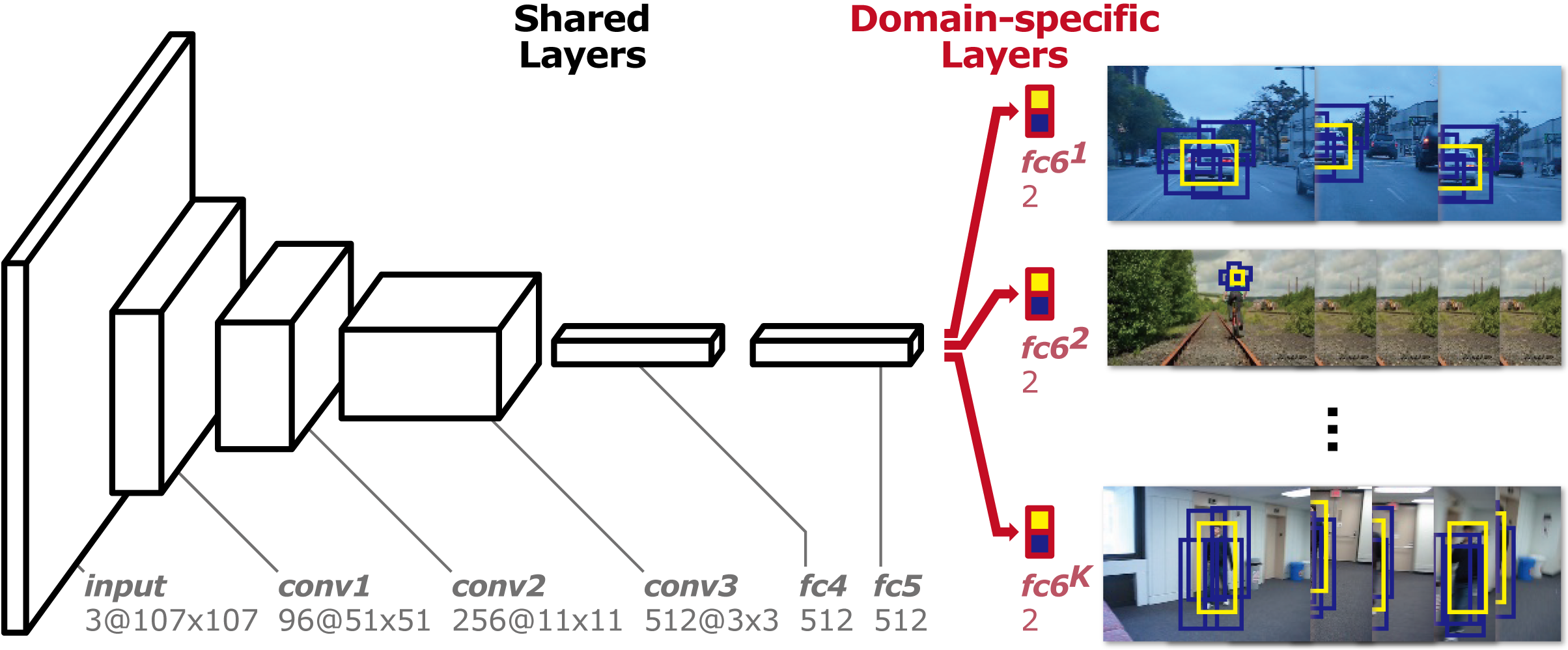
Our algorithm pretrains a CNN using a large set of videos with tracking ground-truths to obtain a generic target representation.
Our network is composed of shared layers and multiple branches of domain-specific layers, where domains correspond to individual training sequences and each branch is responsible for binary classification to identify the target in each domain.
We train the network with respect to each domain iteratively to obtain generic target representations in the shared layers.
When tracking a target in a new sequence, we construct a new network by combining the shared layers in the pretrained CNN with a new binary classification layer, which is updated online.
Online tracking is performed by evaluating the candidate windows randomly sampled around the previous target state.
The proposed algorithm illustrates outstanding performance compared with state-of-the-art methods in existing tracking benchmarks.