Summary
• Introducing an automatic painting approach for 3D scene.
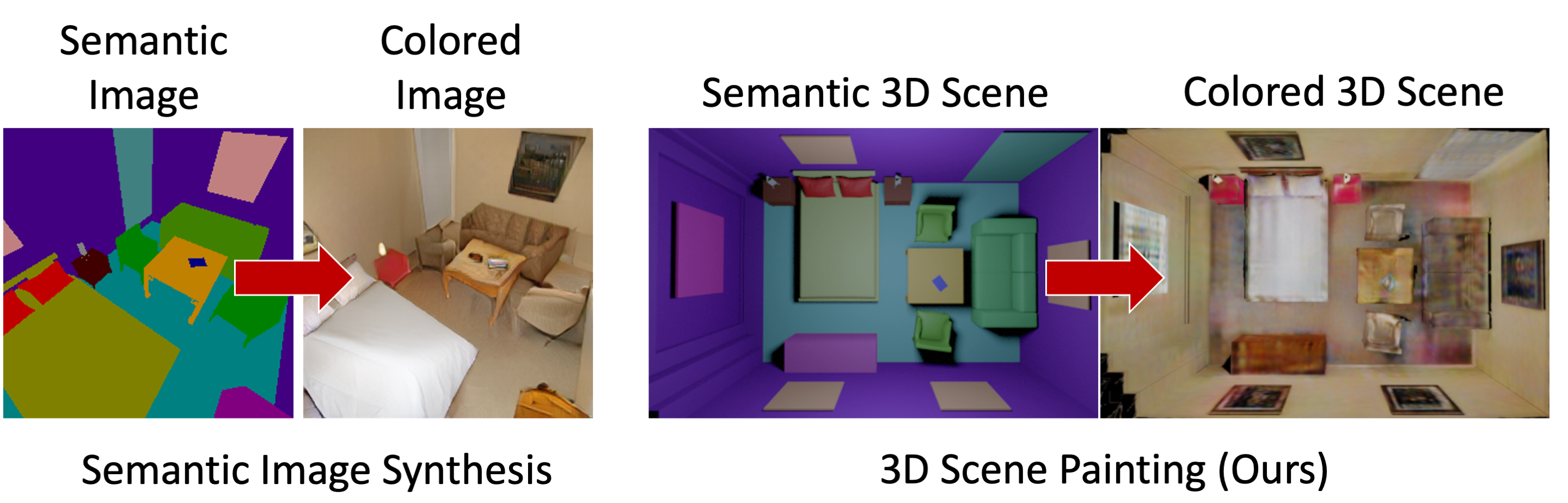
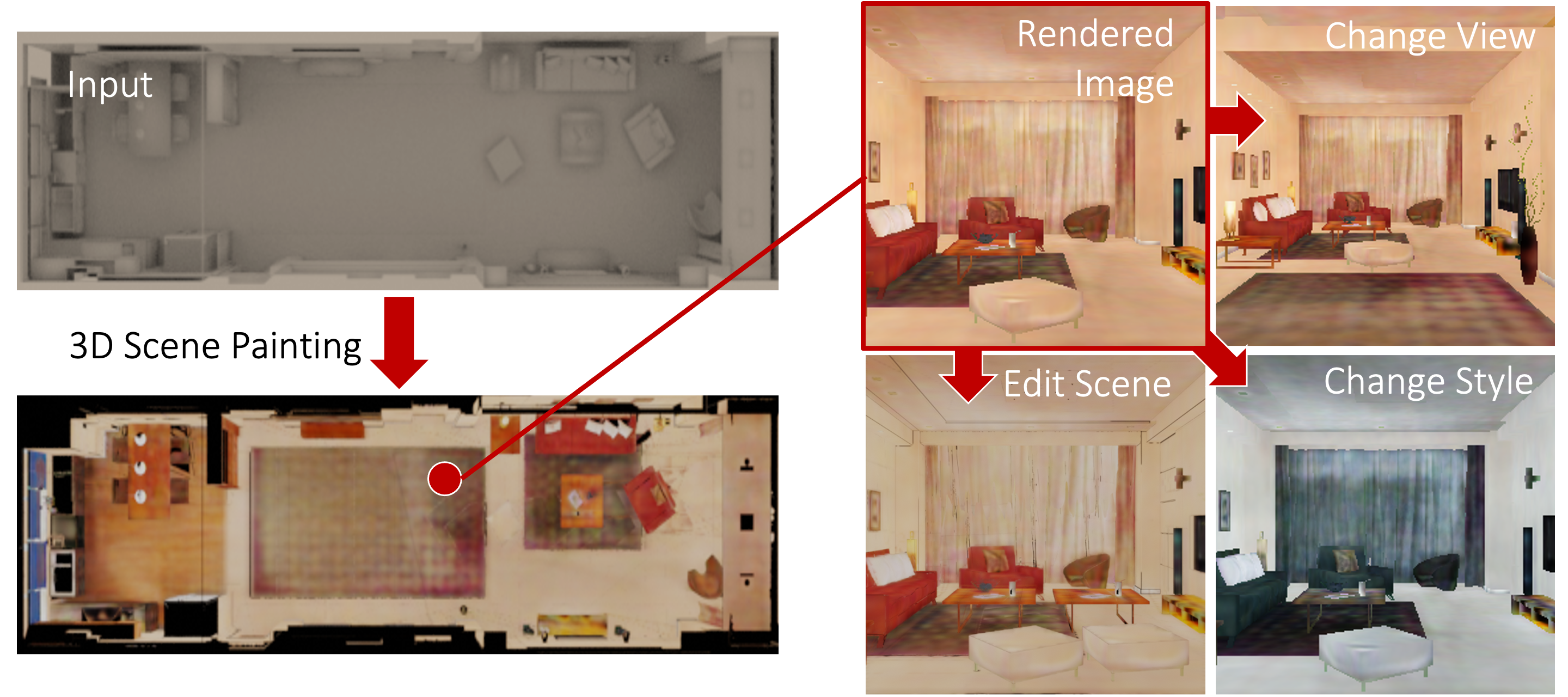
• The images are rendered from colored 3D scenes and provide a way to change viewpoints, scene style manipulation, and scene editing.
| Jaebong Jeong | Janghun Jo | Sunghyun Cho | Jaesik Park | ||||||||||||||||||||||||||
| POSTECH GSAI & CSE | |||||||||||||||||||||||||||||
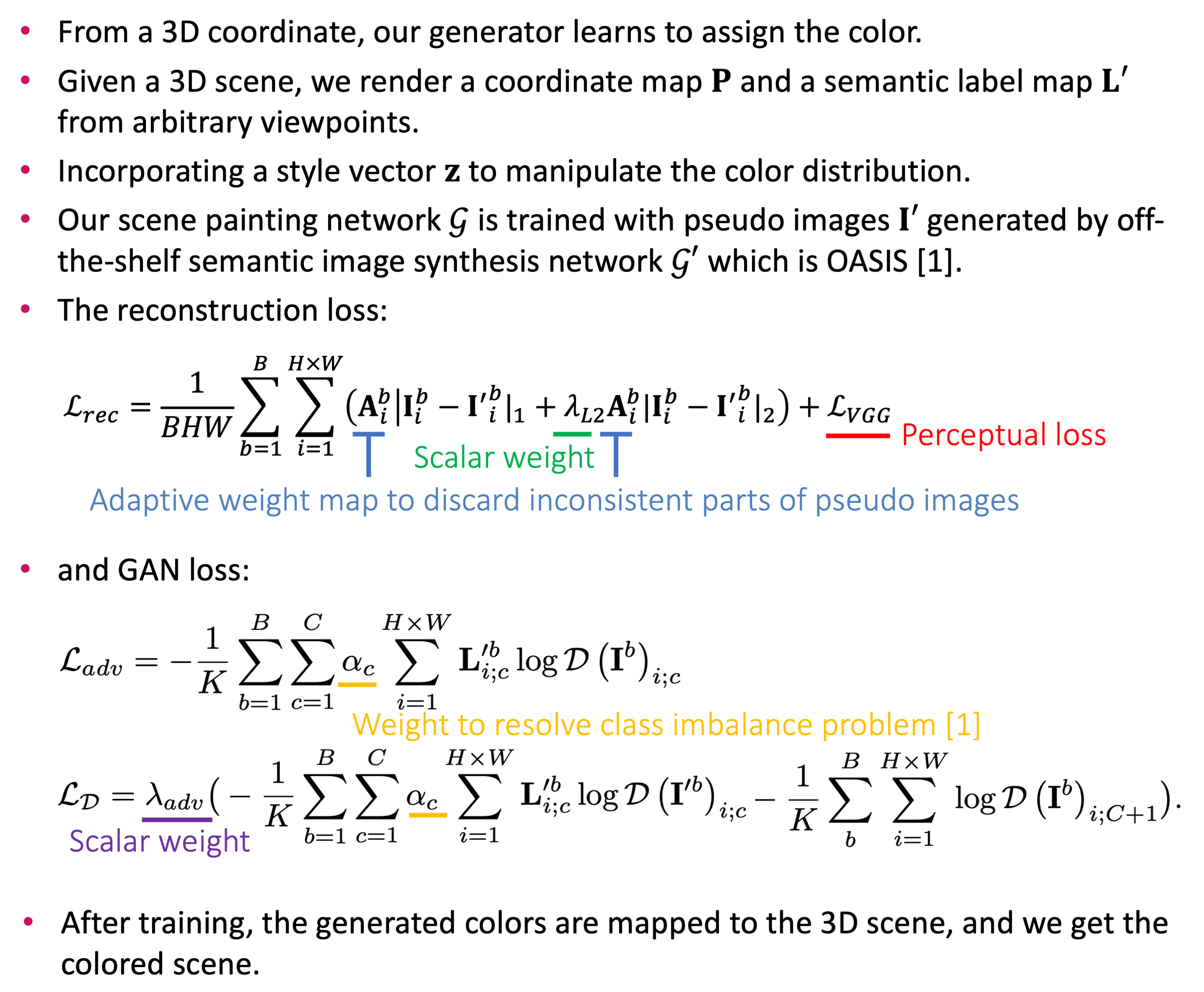
We propose a novel approach to 3D scene painting using a configurable 3D scene layout. Our approach takes a 3D scene with semantic class labels as input and trains a 3D scene painting network that synthesizes color values for the input 3D scene. We exploit an off-the-shelf 2D semantic image synthesis method to teach the 3D painting network without explicit color supervision. Experiments show that our approach produces images with geometrically correct structures and supports scene manipulation, such as the change of viewpoint, object poses, and painting style. Our approach provides rich controllability to synthesized images in the aspect of 3D geometry.
• Introducing an automatic painting approach for 3D scene.
• The images are rendered from colored 3D scenes and provide a way to change viewpoints, scene style manipulation, and scene editing.
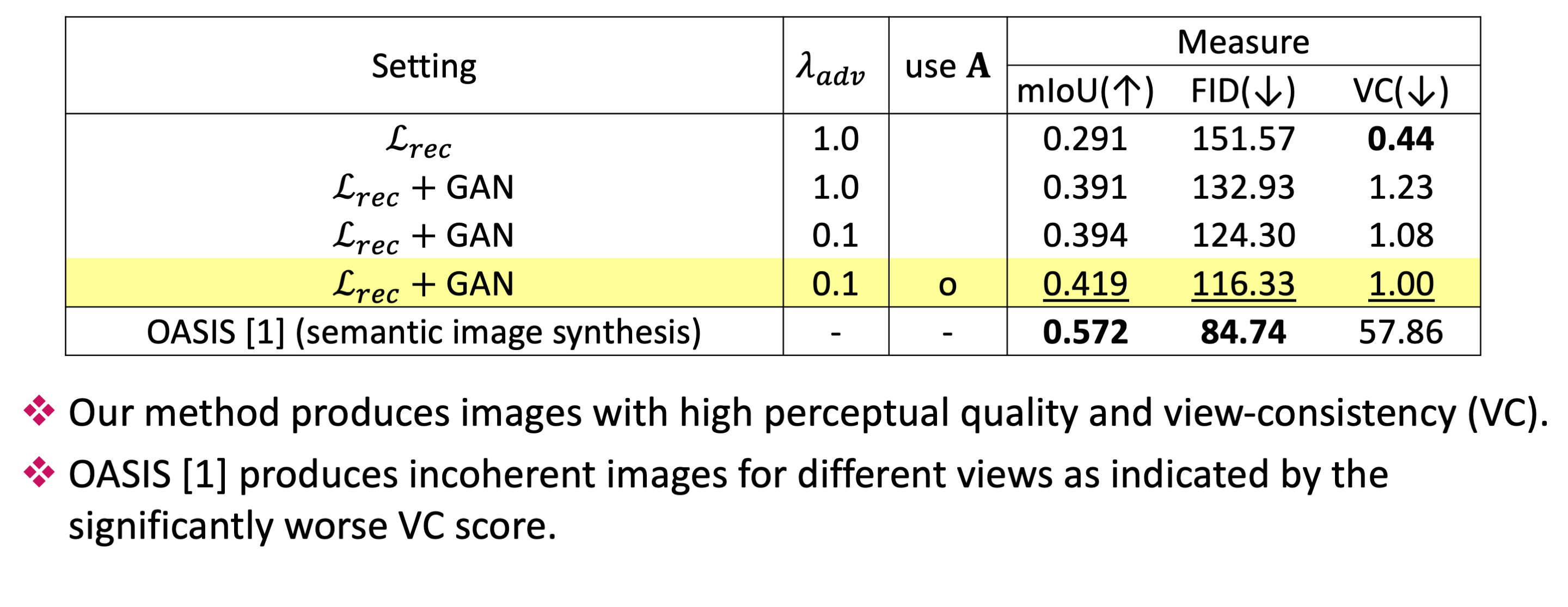
• (left) is the label map, (middle) is the pseudo image from OASIS [1], and (right) is the output of our scene painting network.
• We synthesize the images frame by frame and concatenate the outputs. Our result is more consistent compared to the pseudo image.
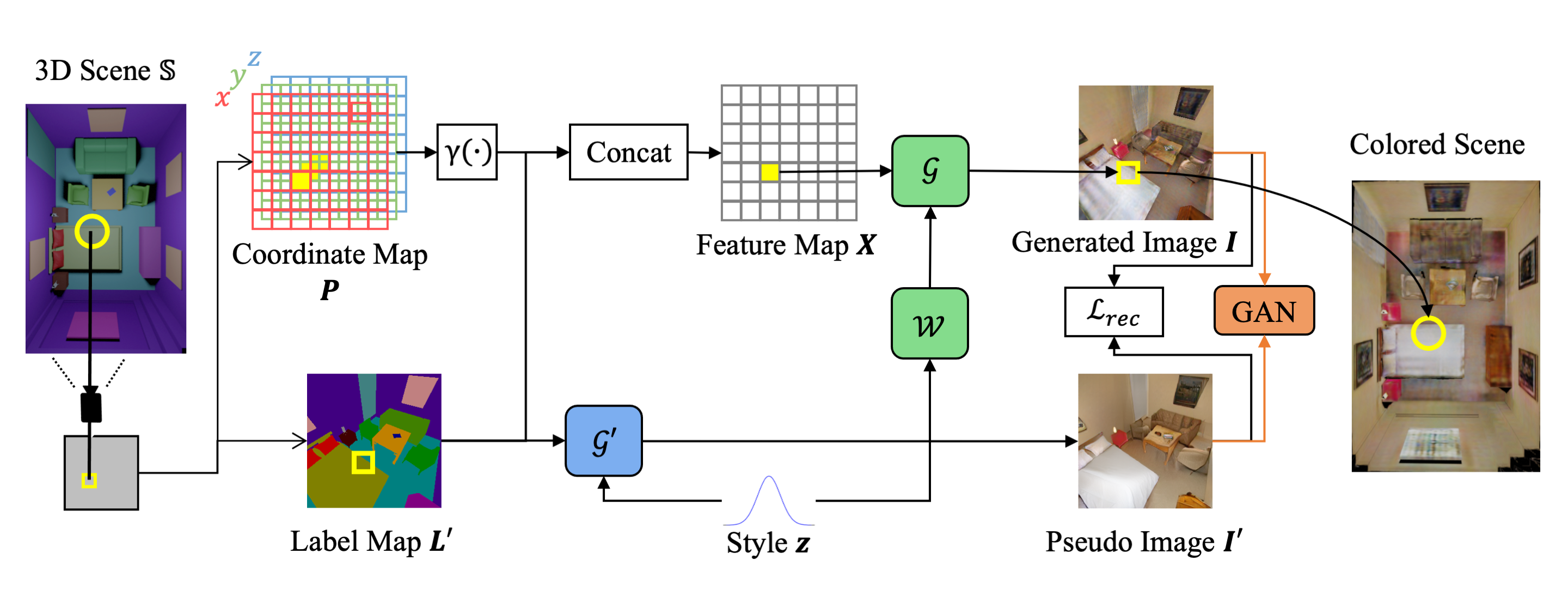
Figure of overview architecture. Learn 3D scene painting without ground-truth colored 3D scenes by adopting pretrained 2D semantic image synthesis network




This work was partly supported by IITP grants funded by the Korea government (MSIT) (2019-0-01906: Artificial Intelligence Graduate School Program (POSTECH) and 2020-0-01649: High-Potential Individuals Global Training Prog.) and by Ministry of Culture, Sports and Tourism (R2021040136: Development of meta-verse contents based on XR & AI)
We're preparing.
[1] Sushko, Vadim et al. “You Only Need Adversarial Supervision for Semantic Image Synthesis.” ICLR 2021