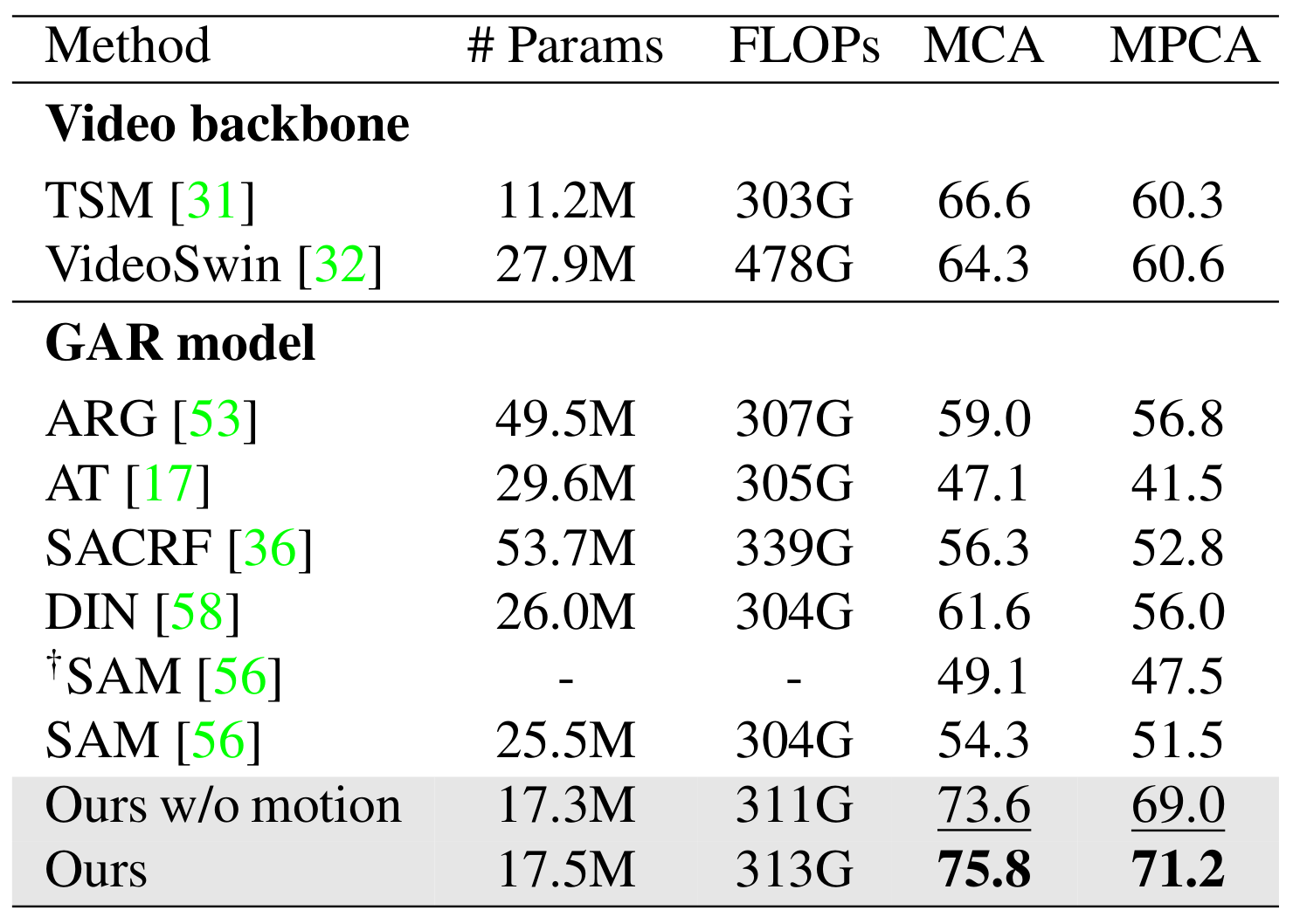
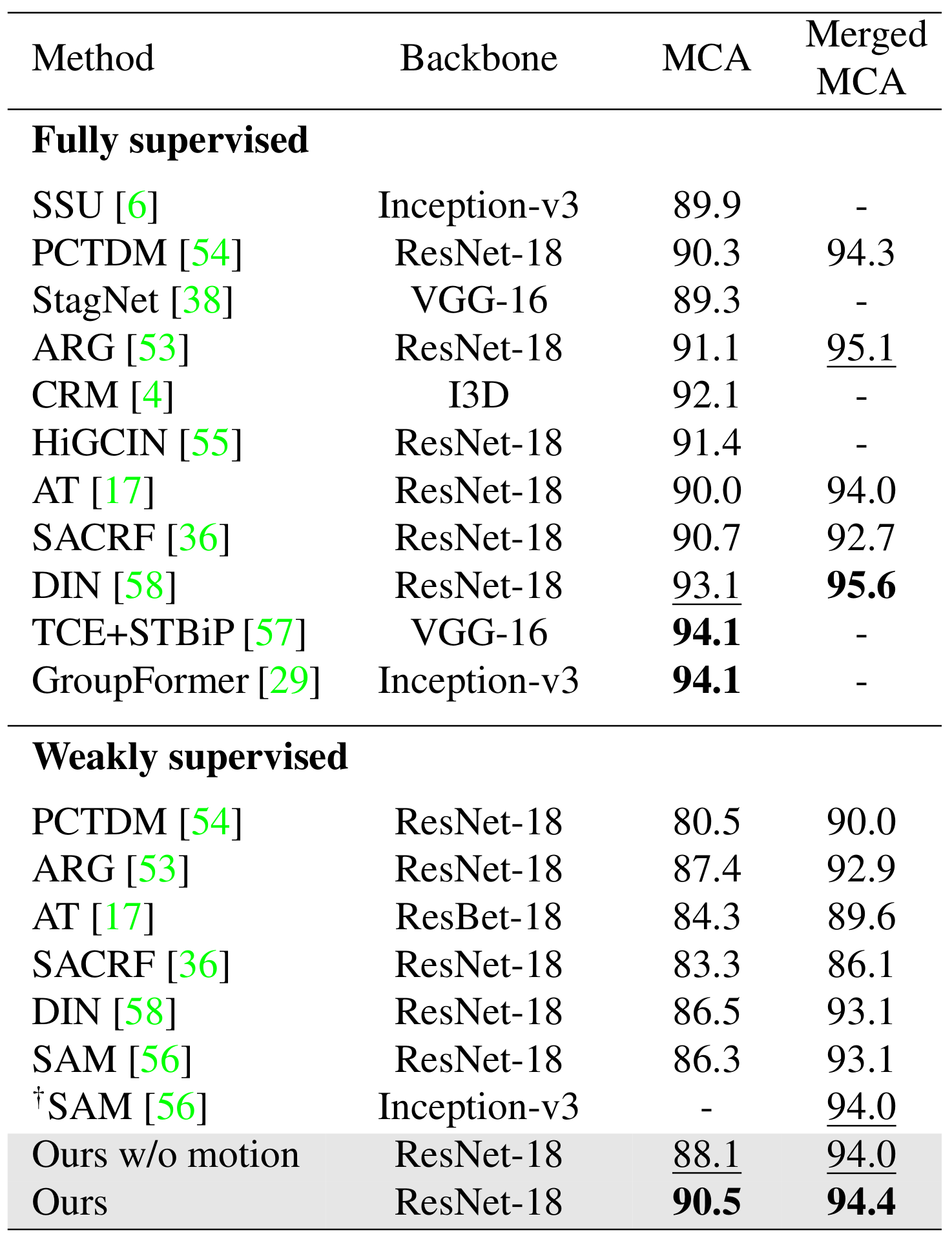
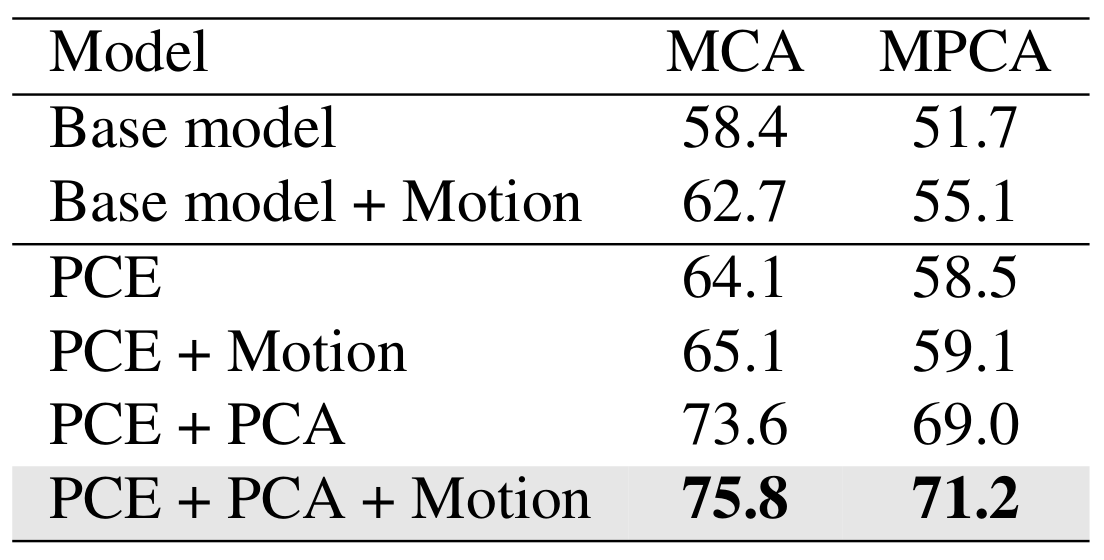
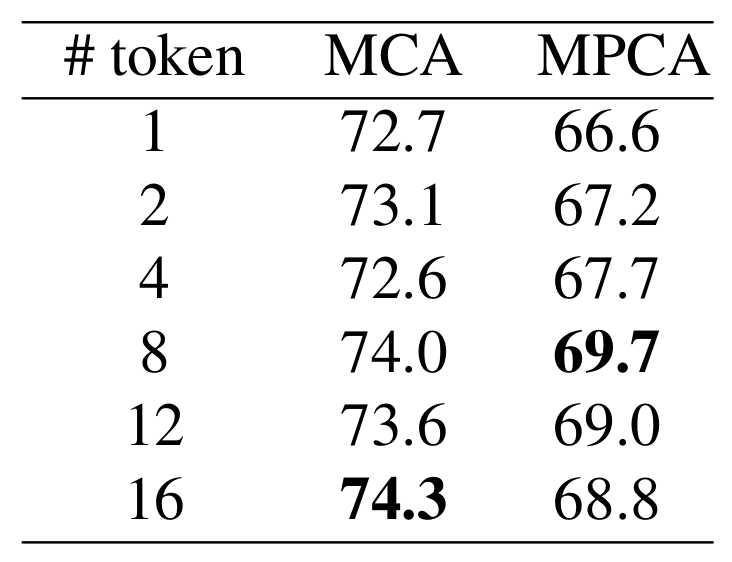
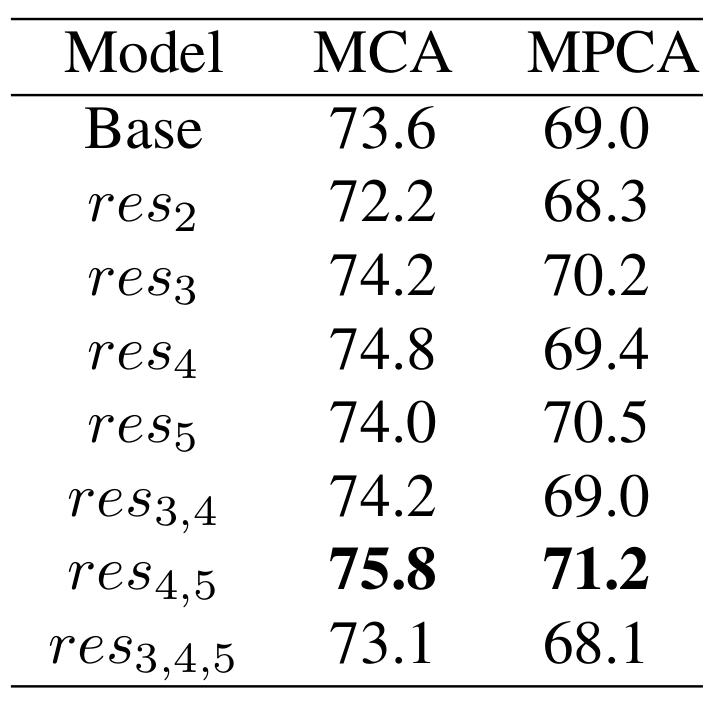
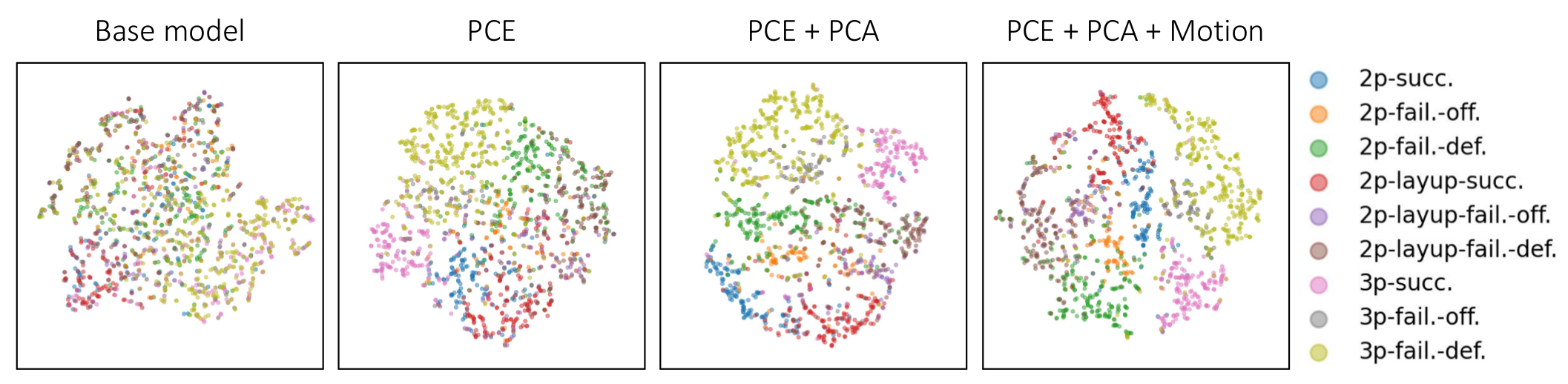
Proposed Method
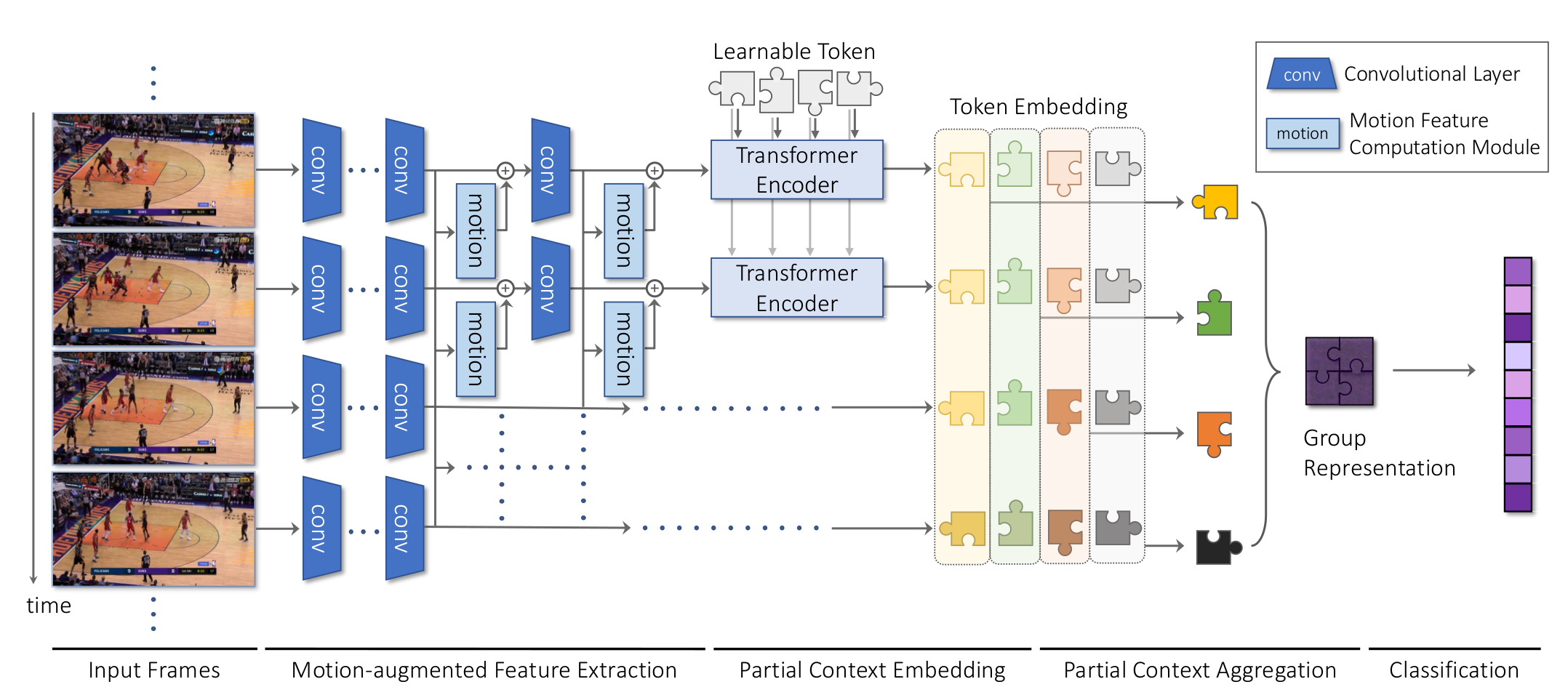
Figure 1. Overall architecture of our model. A CNN incorporating motion feature computation modules extracts a motion-augmented feature map per frame. At each frame, a set of learnable tokens (unpainted pieces of Jigsaw puzzles) is embedded to localize clues useful for group activity recognition through the attention mechanism of the transformer encoder. The token embeddings (painted pieces of Jigsaw puzzles) are then fused to form a group representation in two steps: First aggregate embeddings of the same token (pieces with the same shape) across time, and then aggregate the results of different tokens (pieces with different shapes and colors). Finally, the group representation is fed into the classifier which predicts group activity class scores.