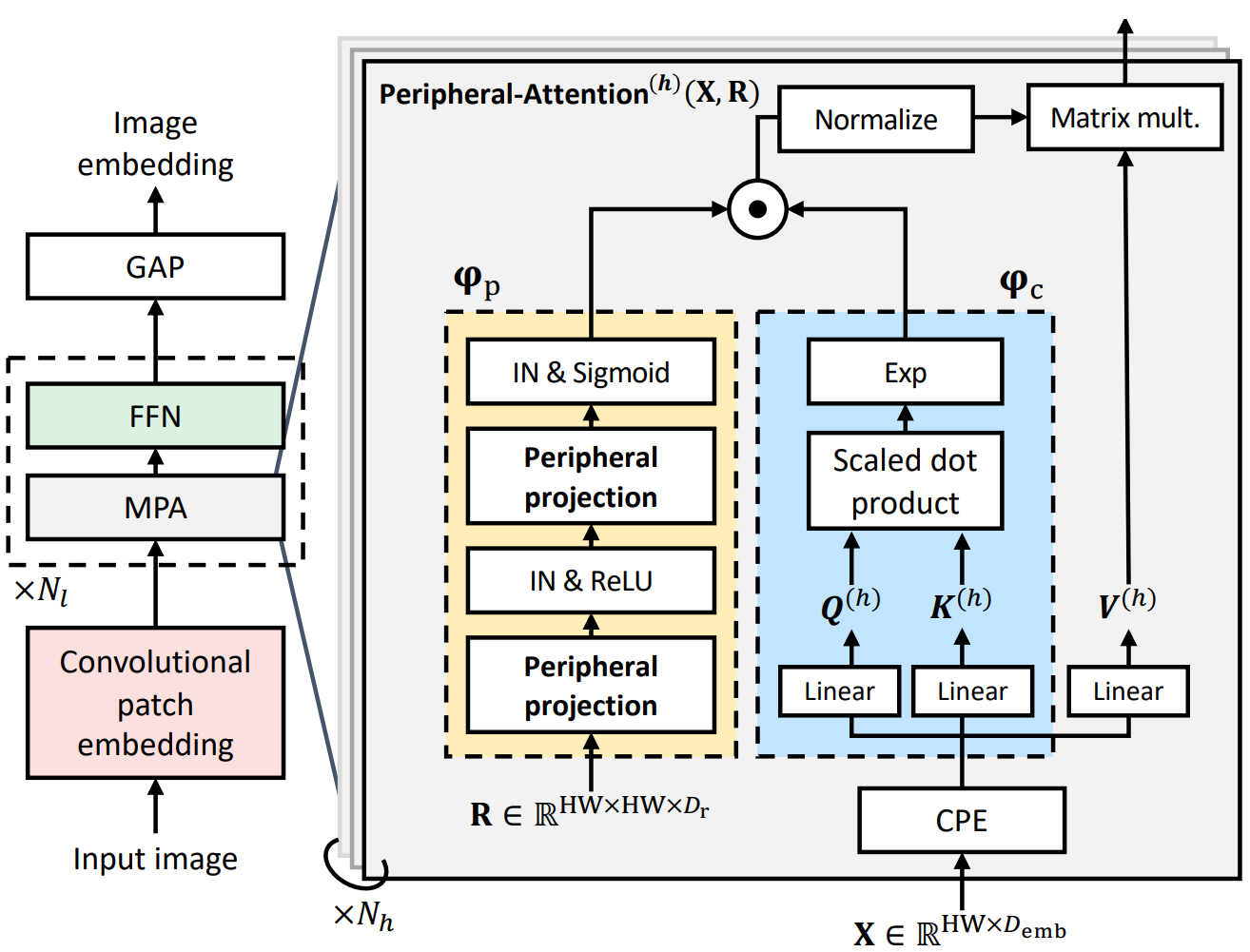
Experimental analyses
1. Learned attentions of PerViT
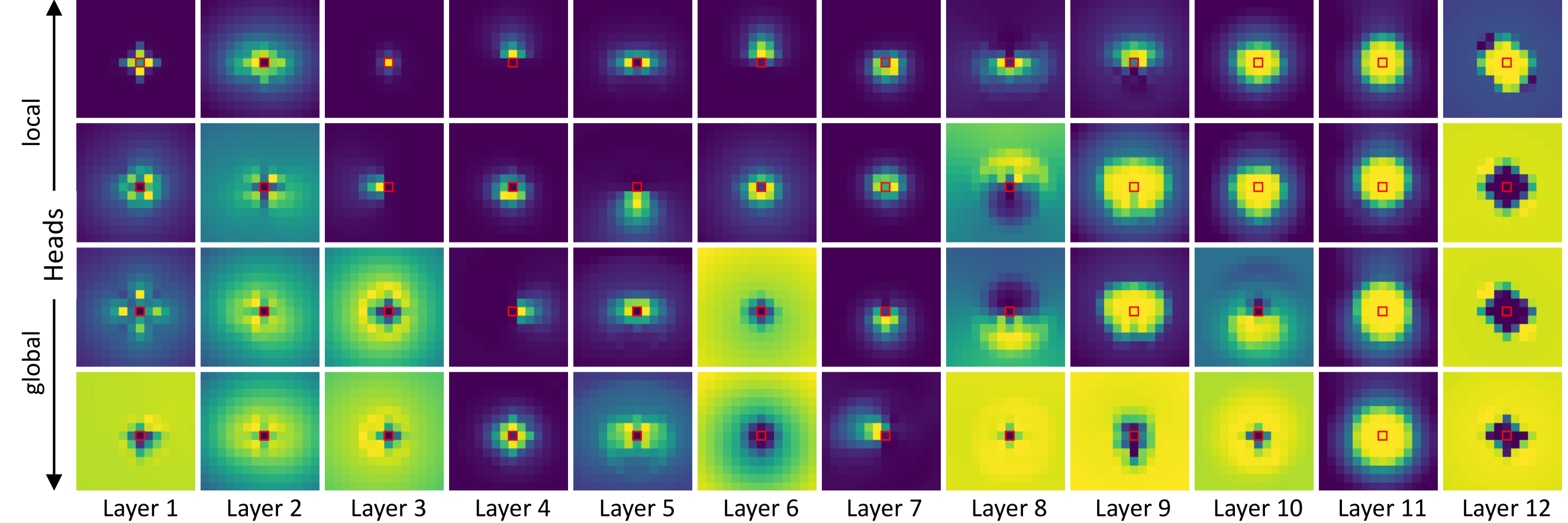
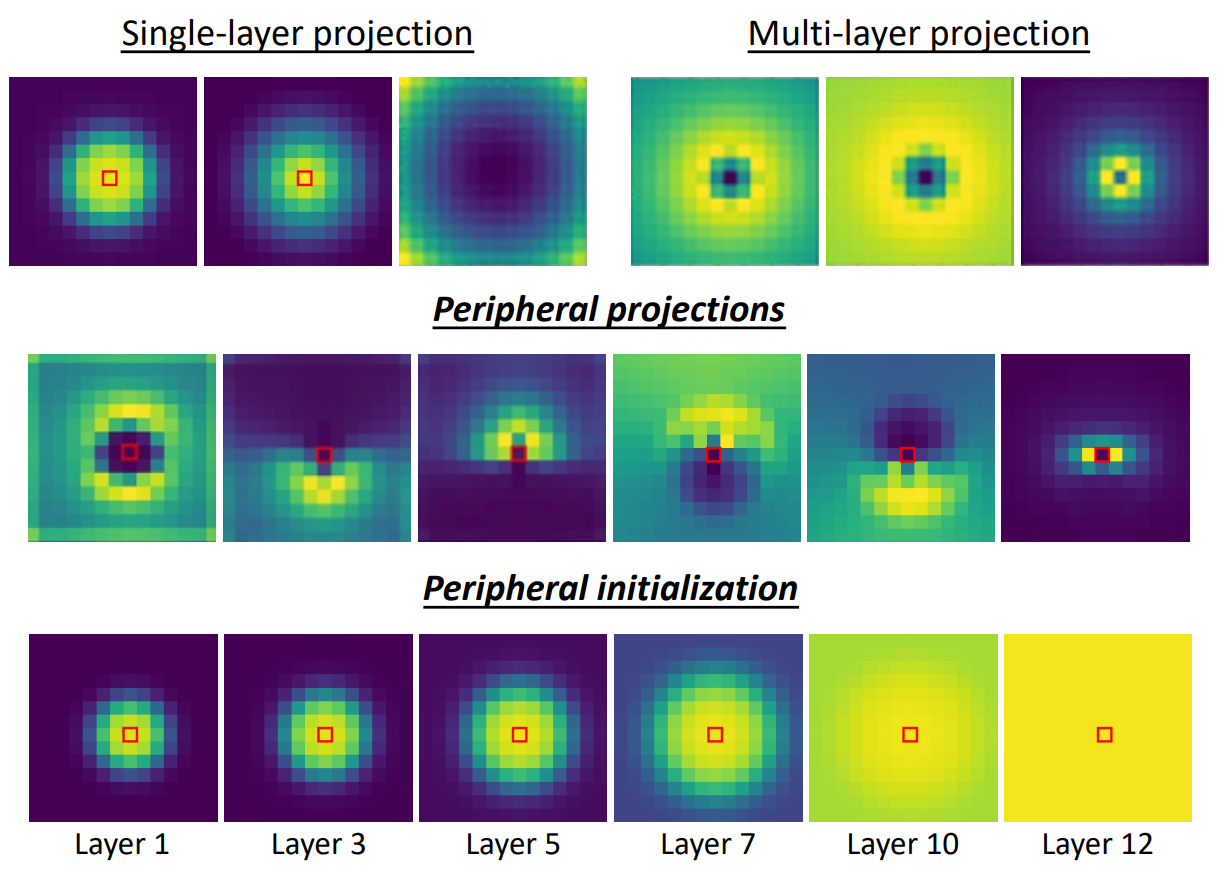
Figure 4.
Learned position-based attention Φp of PerViT-Tiny.
The query position is given at the center.
Without any special supervisions, the four attended regions (heads) in most layers are learned to complement each other to cover the entire visual field, capturing different visual aspects at each peripheral region, similarly to human peripheral vision as illustrated in Figure.1.
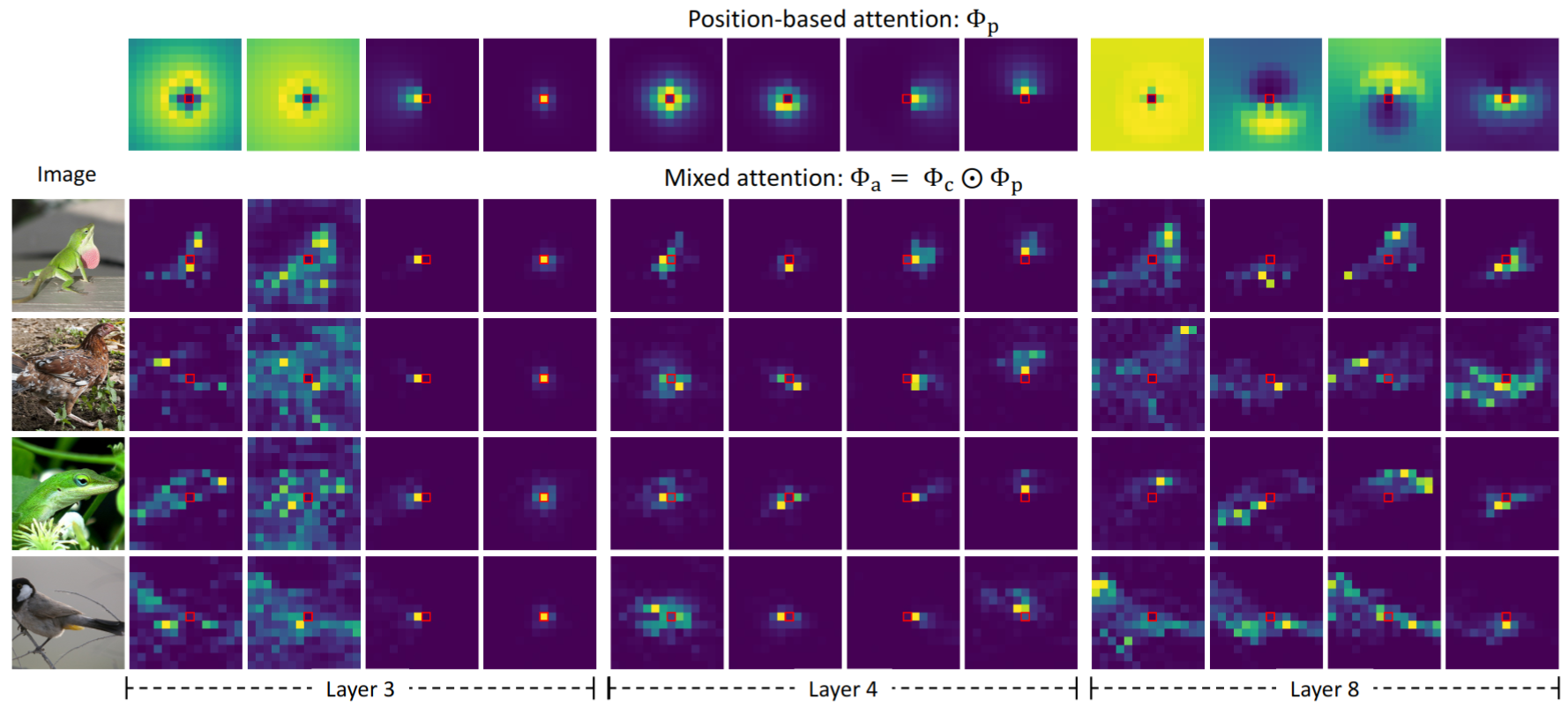
Figure 5.
Learned position-based Φp and mixed Φa attentions of PerViT-Tiny for layers 3, 4 and 8.
The mixed attentions Φa at Layer 4 are formed dynamically (Φc) within statically-formed region (Φp) while the attentions Φa at Layer 8 weakly exploit position information (Φp) to form dynamic attentions.
The results reveal that Φp plays two different roles; it imposes semi-dynamic attention if the attended region is focused in a small area whereas it serves as position bias injection when the attended region is relatively broad.
In the paper, we constructively prove that an MPA layer in extreme case of semi-dynamic attention/position bias injection is in turn convolution/multi-head self-attention, naturally generalizing the both transformations.
2. The inner workings of PerViT
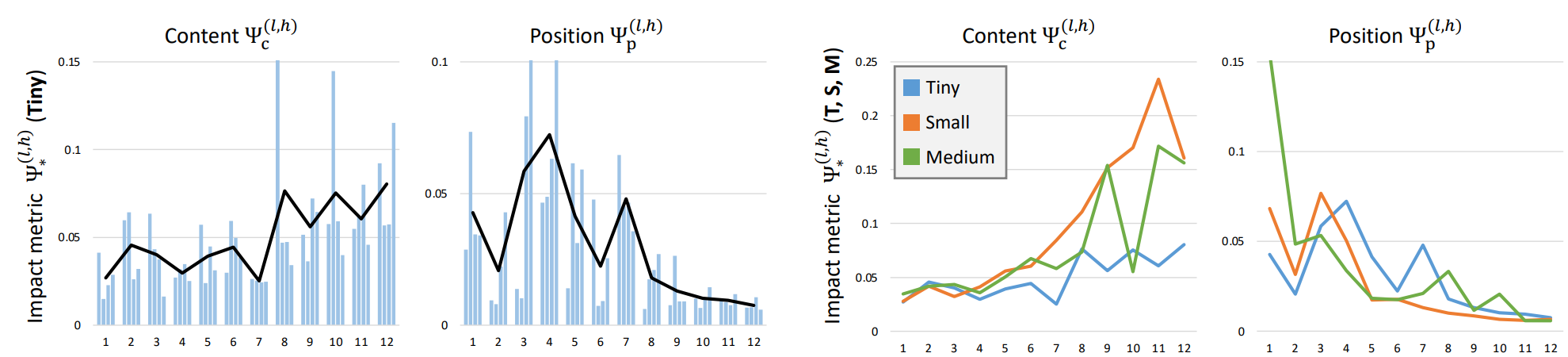
Figure 6.
The measure of impact (x-axis: layer index, y-axis: the impact metric).
Each bar graph shows the measure of a single head (4 heads at each layer), and the solid lines represent the trendlines which follow the average values of layers. (left: results of PerViT-T. right: results of T, S, and M.)
The impact of position-based attention is significantly higher in early processing, transforming features semi-dynamically, while the later layers require less position information, regarding Φp as a minor position bias.
Note that the impact measures of four heads (bar graphs) within each layer show high variance, implying that the network evenly utilizes both position and content information simultaneously within each MPA layer (Layer 3 in Figure.5), performing both static/local and dynamic/global transformation in a single-shot.
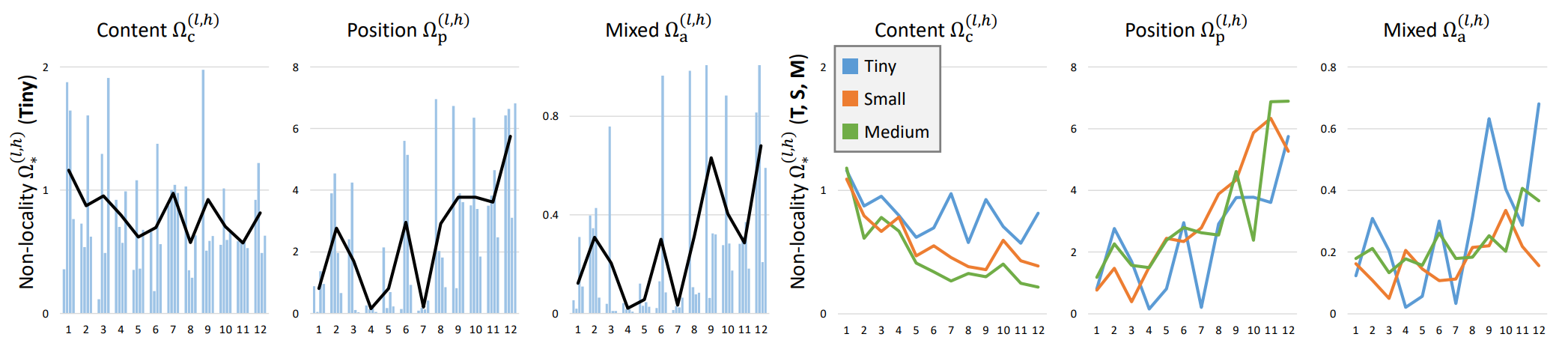
Figure 7.
The measure of nonlocality (x-axis: layer index, y-axis: the nonlocality metric).
We observe a similar trend of locality between Φp and Φa, which reveals the position information play more dominant role over the content information in forming spatial attentions (Φa) for feature transformation.
We also observe that content- and position-based attentions behave conversely; Φc attends globally in early layers, i.e., large scores are distributed over the whole spatial region, while being relatively local in deeper layers.
3. Evaluation on ImageNet-1K
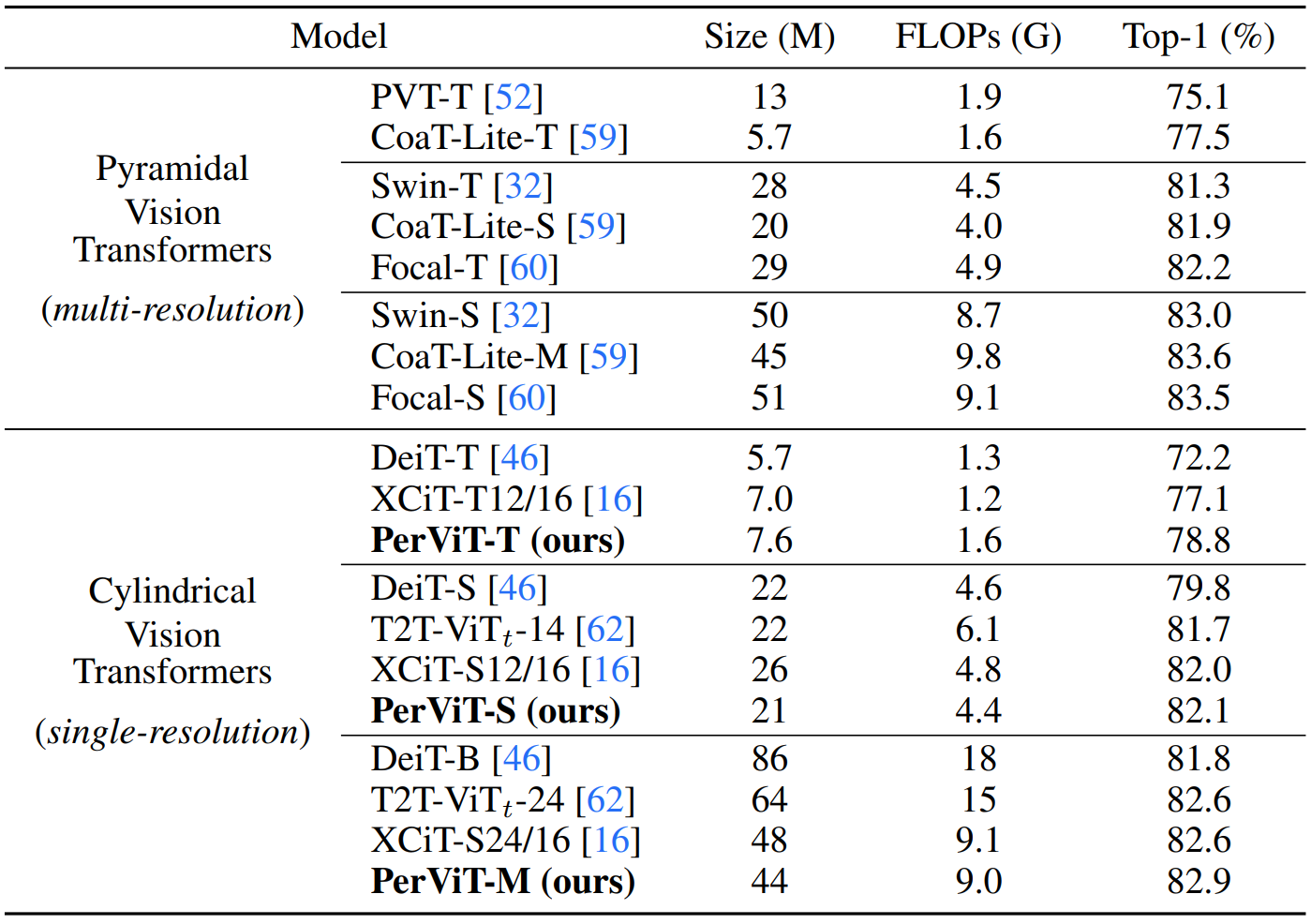
Table 1.
Model performance on ImageNet [B].
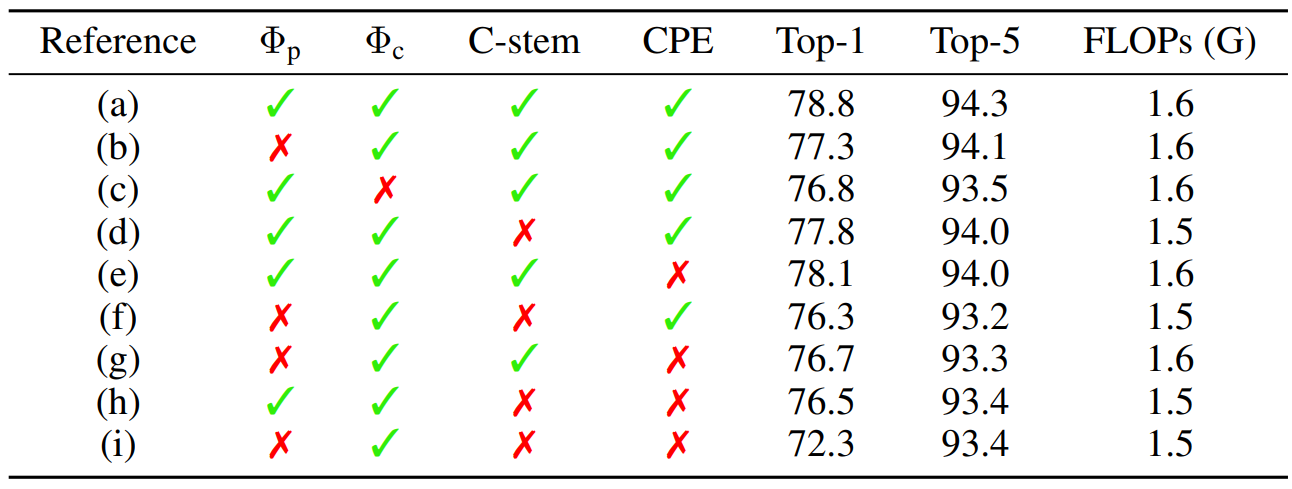
Table 2.
Study on the effect of each component in PerViT.
For additional results and analyses, please refer to our paper available on [arXiv].