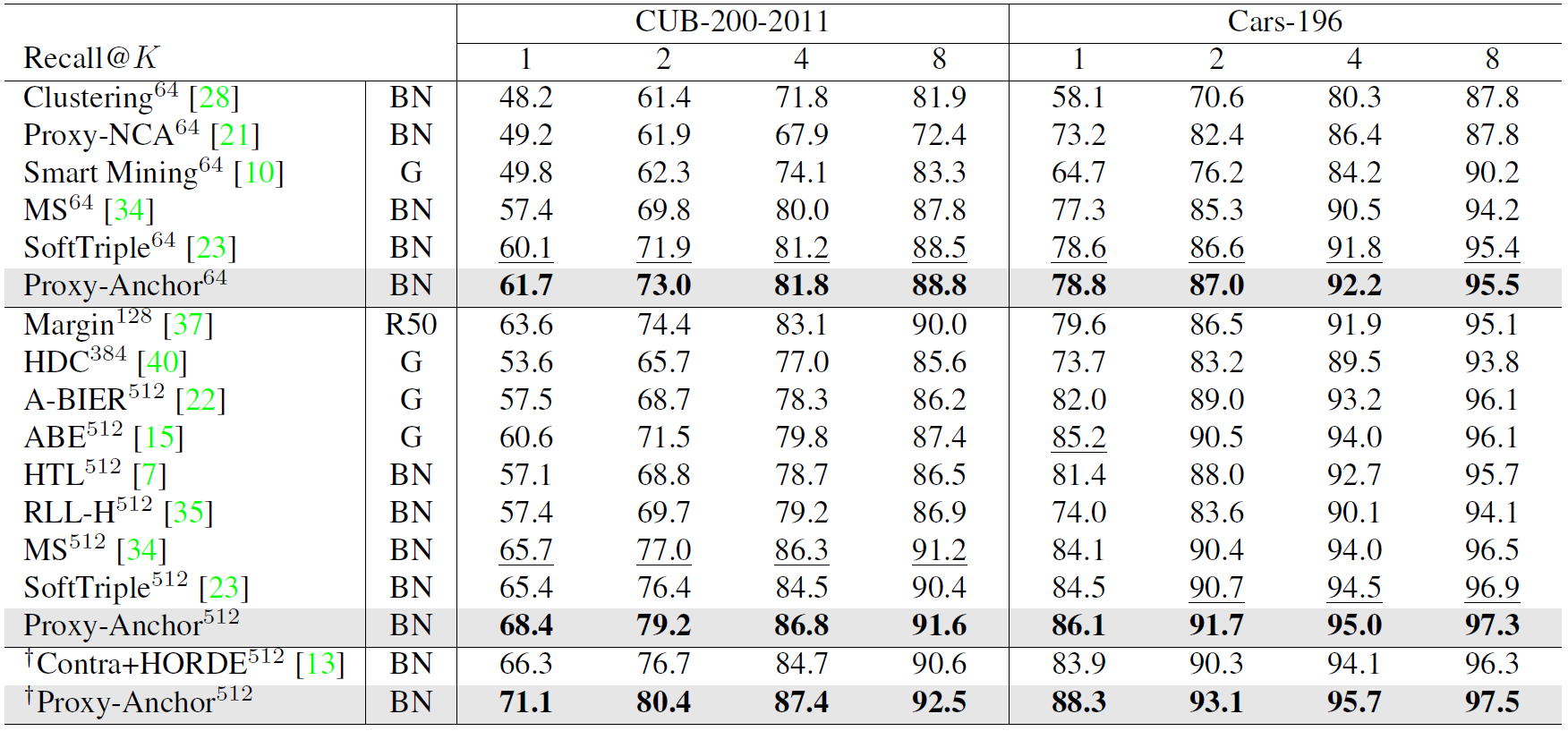
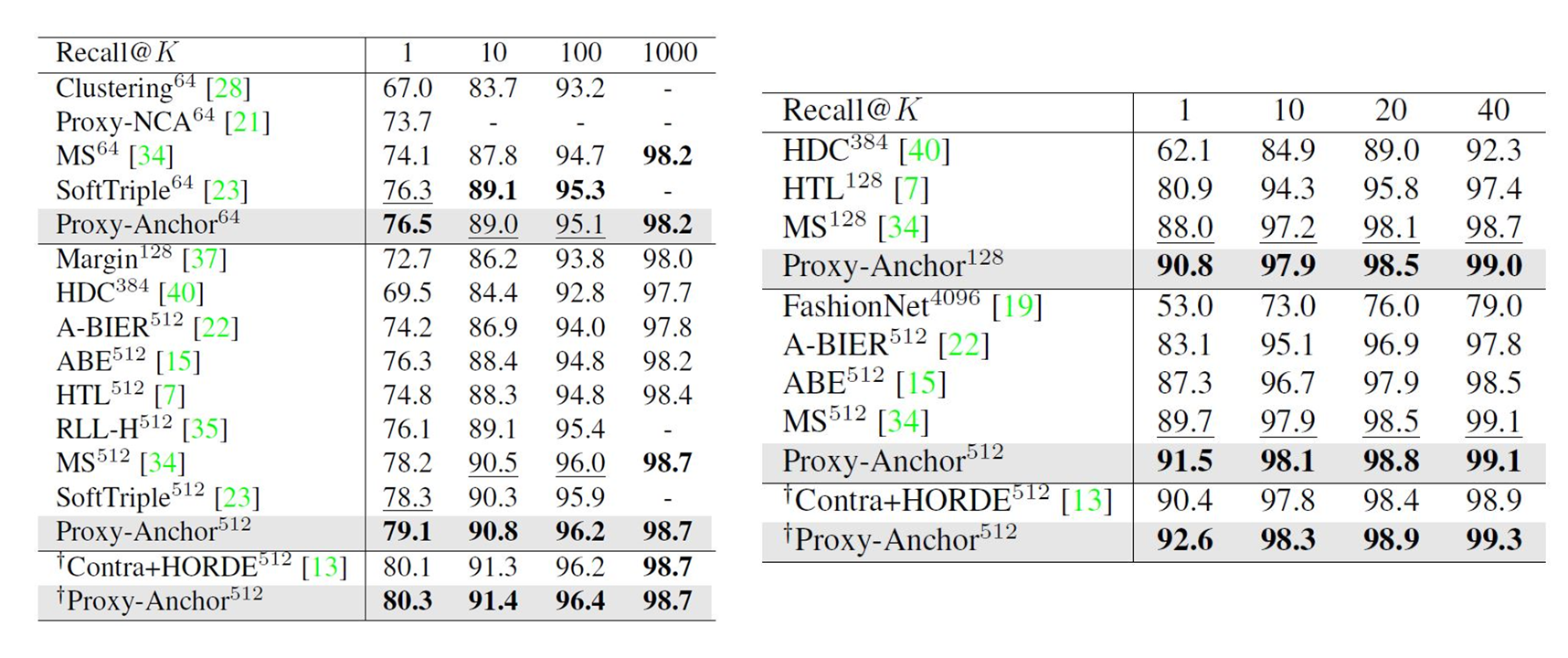
Comparison Between Other Metric Learning Losses
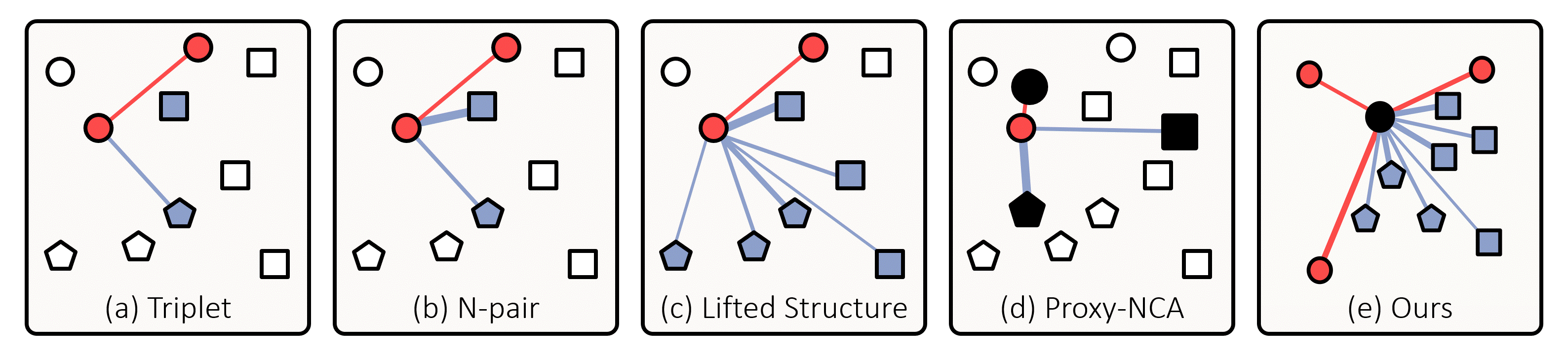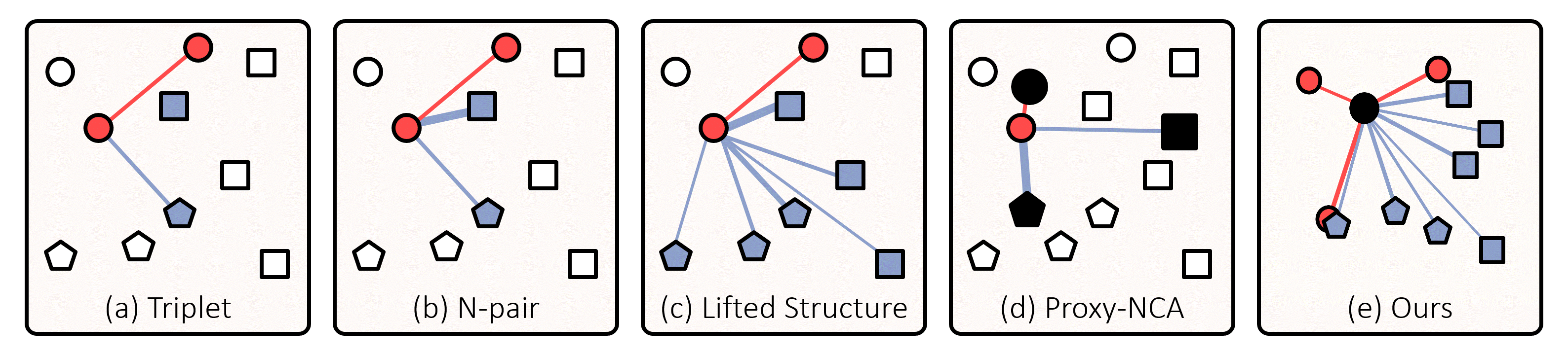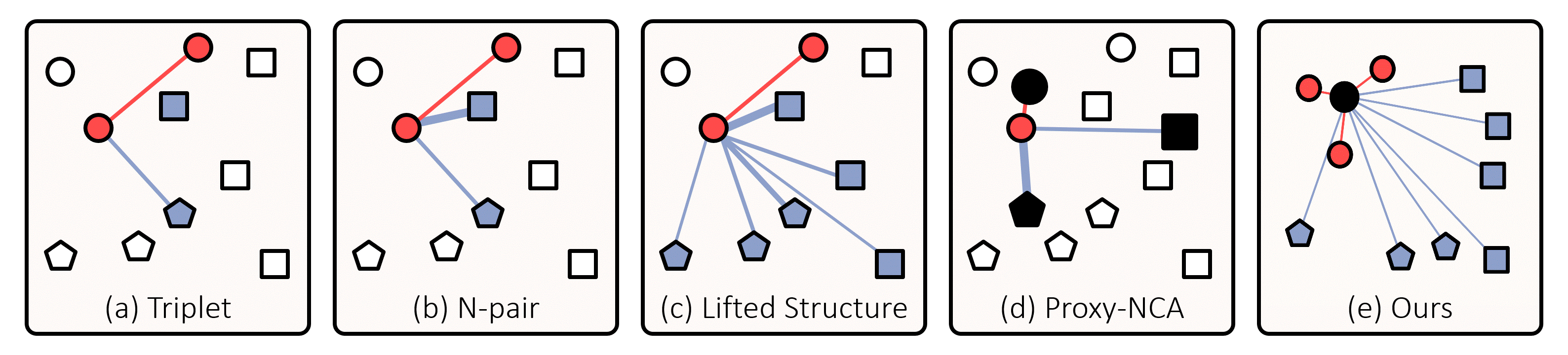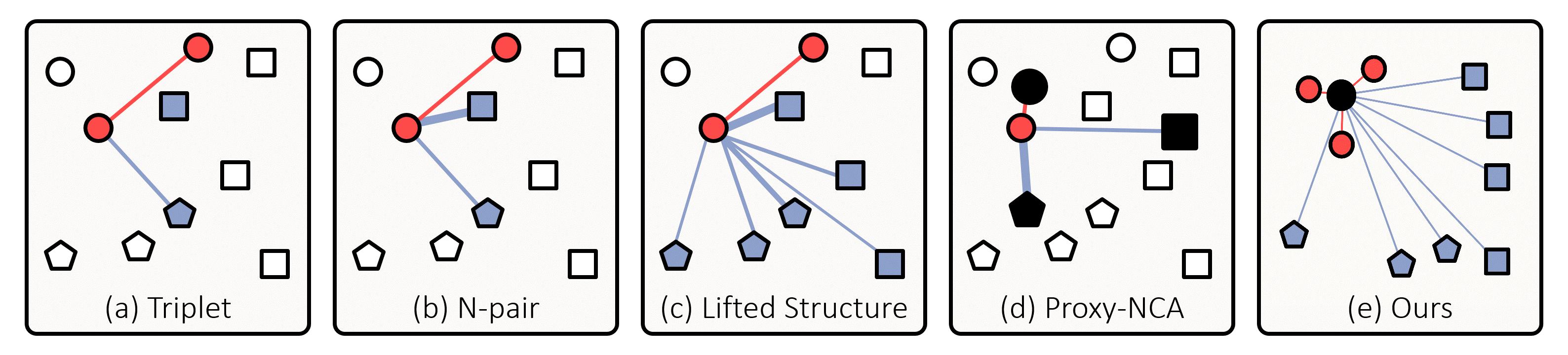
Figure 1. Comparison between popular metric learning losses and ours. Small nodes are embedding vectors of data in a batch, and black ones indicate proxies; their different shapes represent distinct classes. The associations defined by the losses are expressed by edges, and thicker edges get larger gradients. Also, embedding vectors associated with the anchor are colored in red if they are of the same class of the anchor (i.e., positive) and in blue otherwise (i.e., negative). (a) Triplet loss associates each anchor with a positive and a negative data point without considering their hardness. (b) N-pair loss and (c) Lifted Structure loss reflect hardness of data, but do not utilize all data in the batch. (d) Proxy-NCA loss cannot exploit data-to-data relations since it associates each data point only with proxies. (e) Our loss handles entire data in the batch, and associates them with each proxy with consideration of their relative hardness determined by data-to-data relations. See the text for more details.