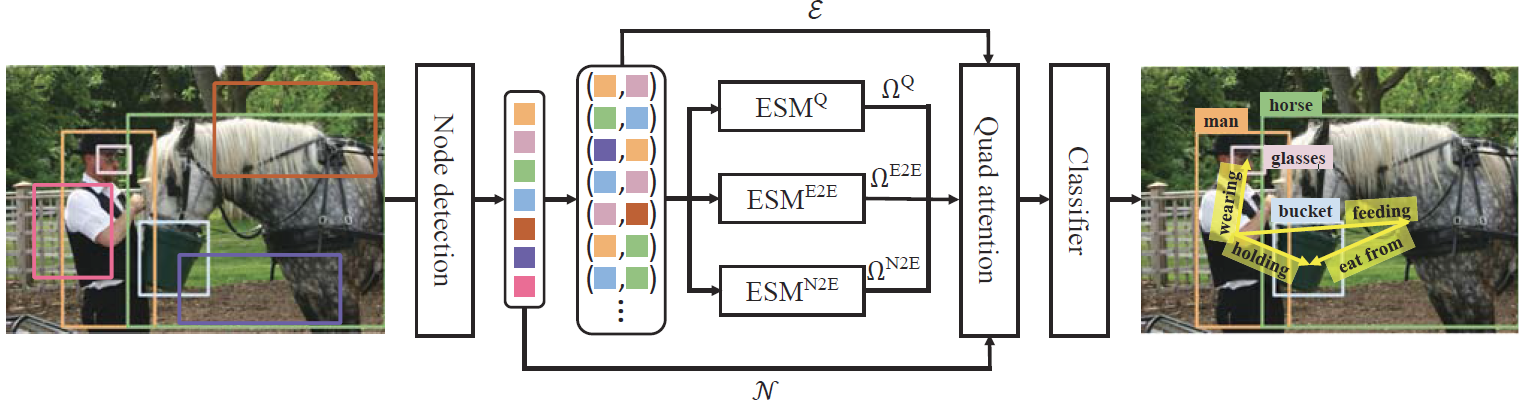
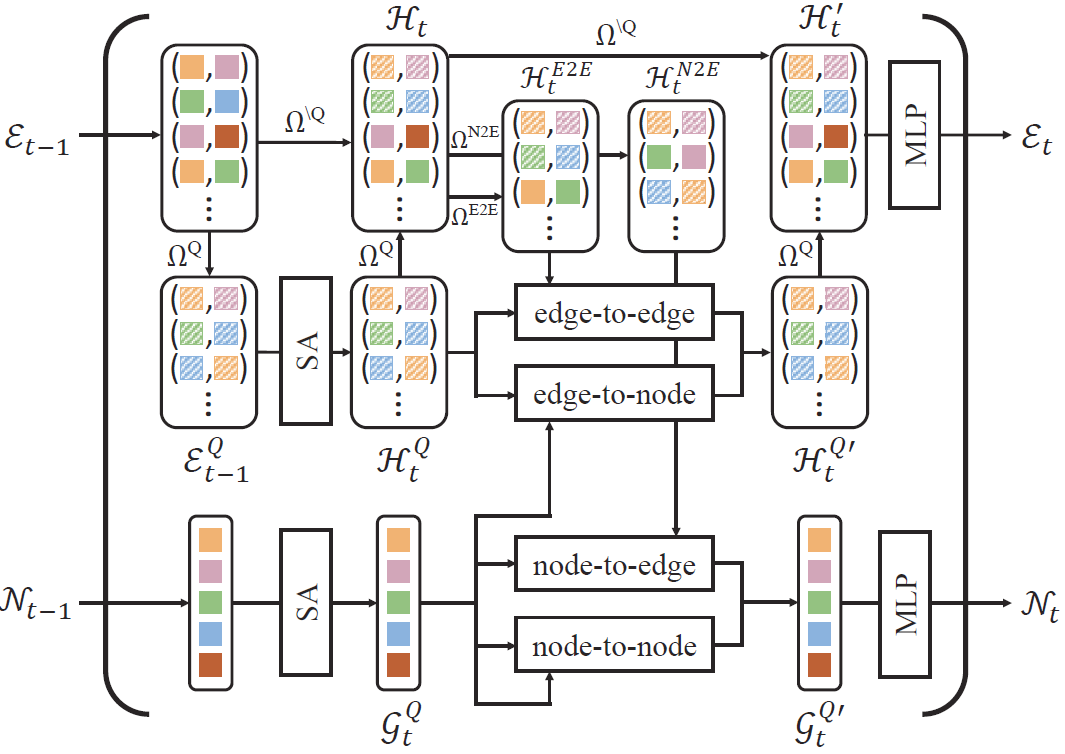
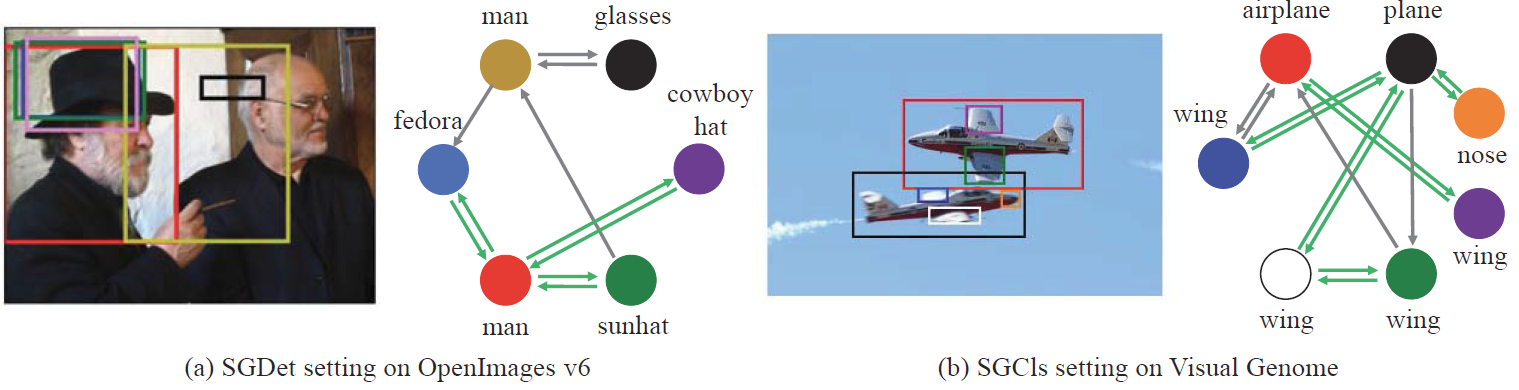
Experimental Analysis
Results on Visual Genome
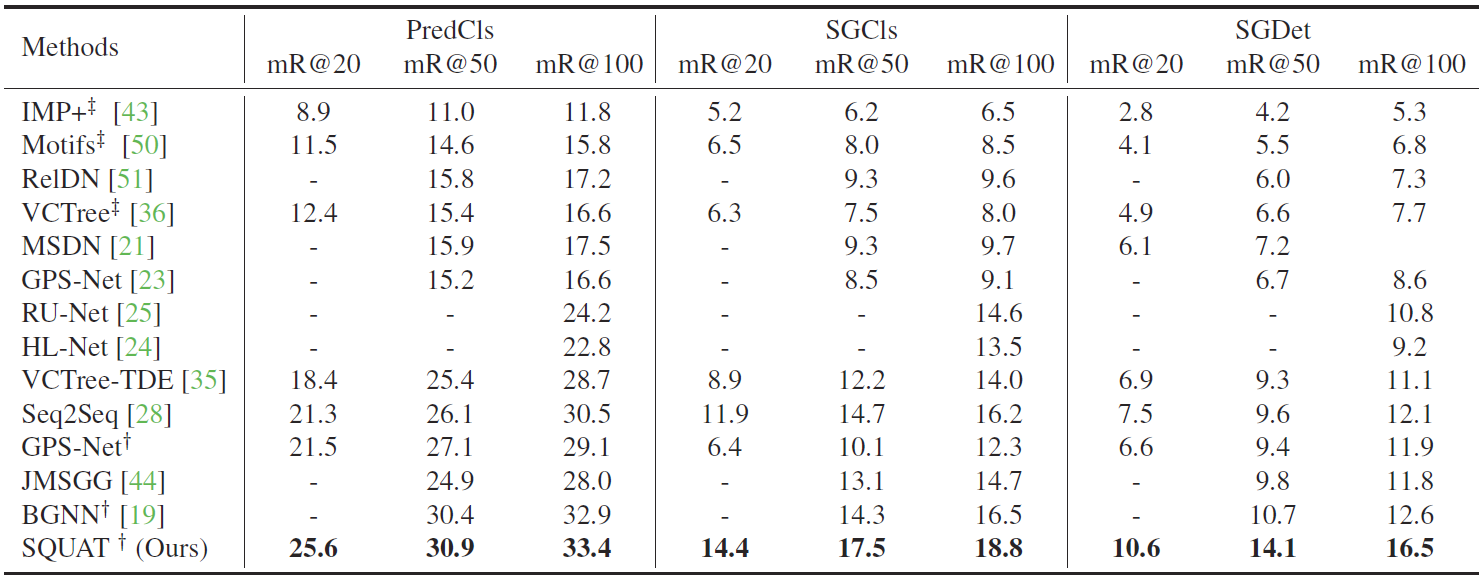
Table 1.
The scene graph generation performance of three subtasks on Visual Genome (VG) dataset with graph constraints. † denotes that the bi-level sampling is applied for the model. ‡ denotes that the results are reported from [A]. SQUAT outperforms the state-of-the-art models on every setting, PredCls, SGCls and SGDet. Especially, SQUAT outperforms the state-of-the-art models by a large margin of 3.9 in mR@100 on the SGDet setting, which is the most realistic and important setting in practice as there is no perfect object detector.
Effect of the edge selection module
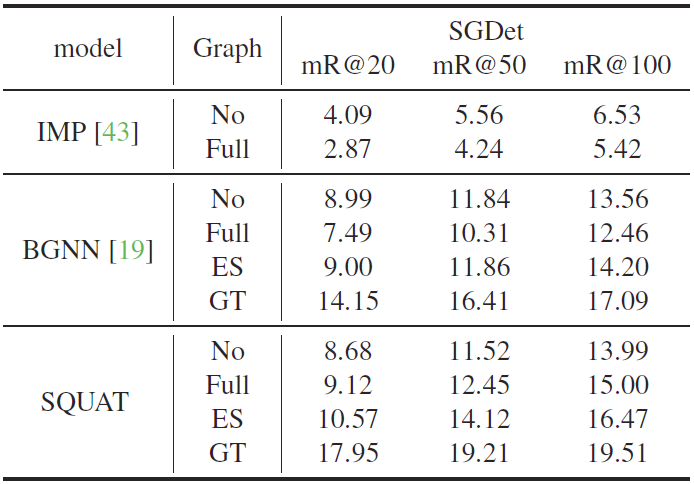
Table 2.
The ablation study on message passing for the scene graph generation. There are four settings depending on which graphs are used in the message passing: No, Full, ES, and GT. Every model with the message passing through ground truth outperforms state-of-the-art models by a substantial margin, showing that removing the invalid edges is crucial for scene graph generation. The edge selection module clearly improves not only the performance of SQUAT but also that of BGNN, the previous state-of-the-art model. It indicates that the edge selection module effectively removes the invalid edges and can be used as a plug-and-play module for message-passing-based scene graph methods.
Ablation Study
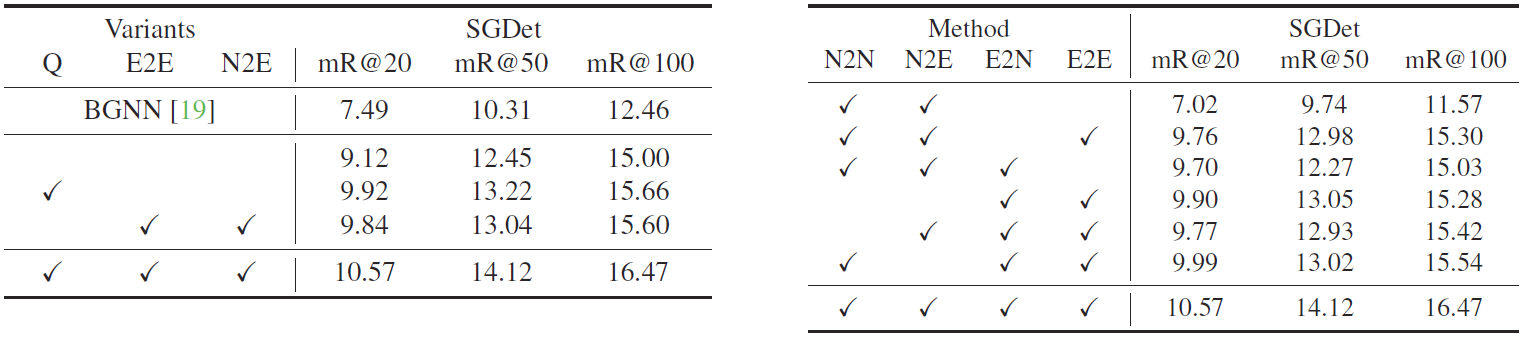
Table 3.
(left) The ablation study on model variants on edge selection. We remove the edge selection module for query selection and key-value selection.
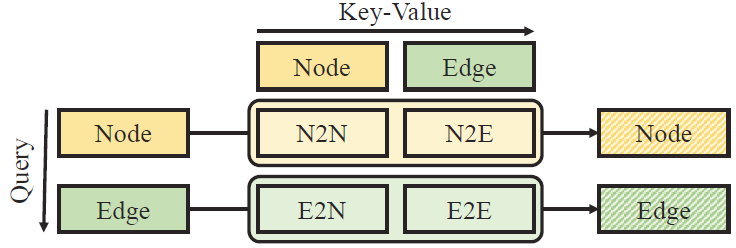
(right) The ablation study on model variants on quad attention. N2N, N2E, E2N, E2E denote the node-to-node, node-toedge,
edge-to-node, and edge-to-edge attentions, respectively.