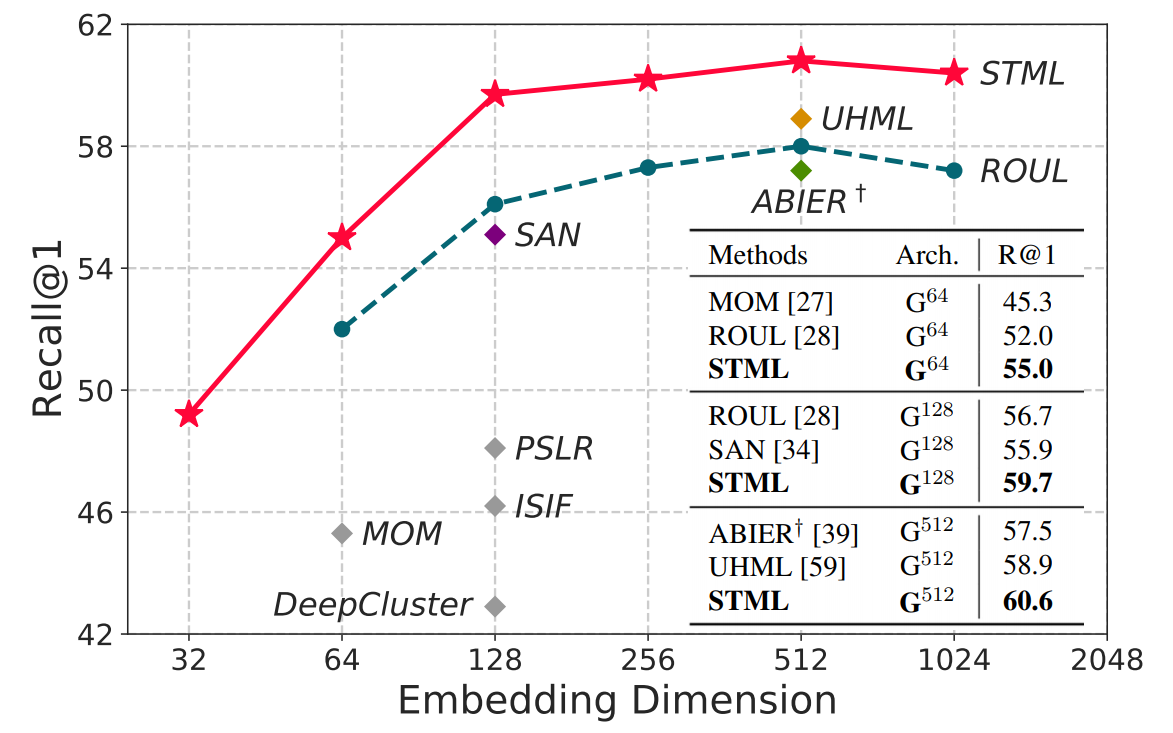
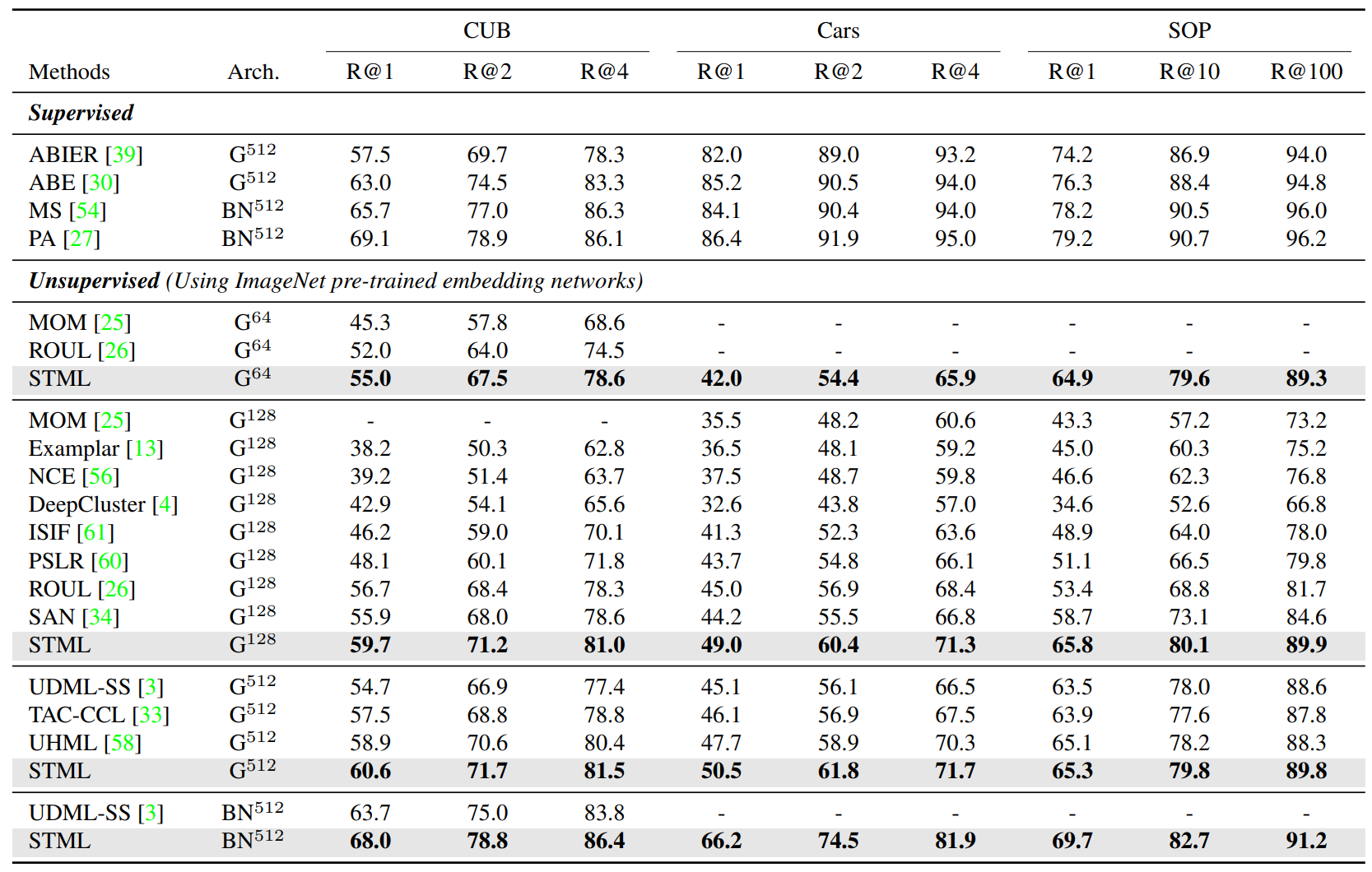
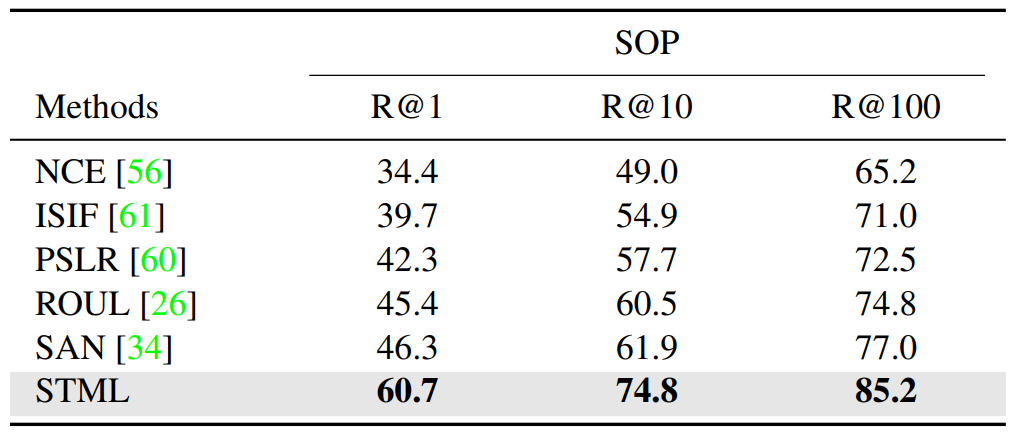
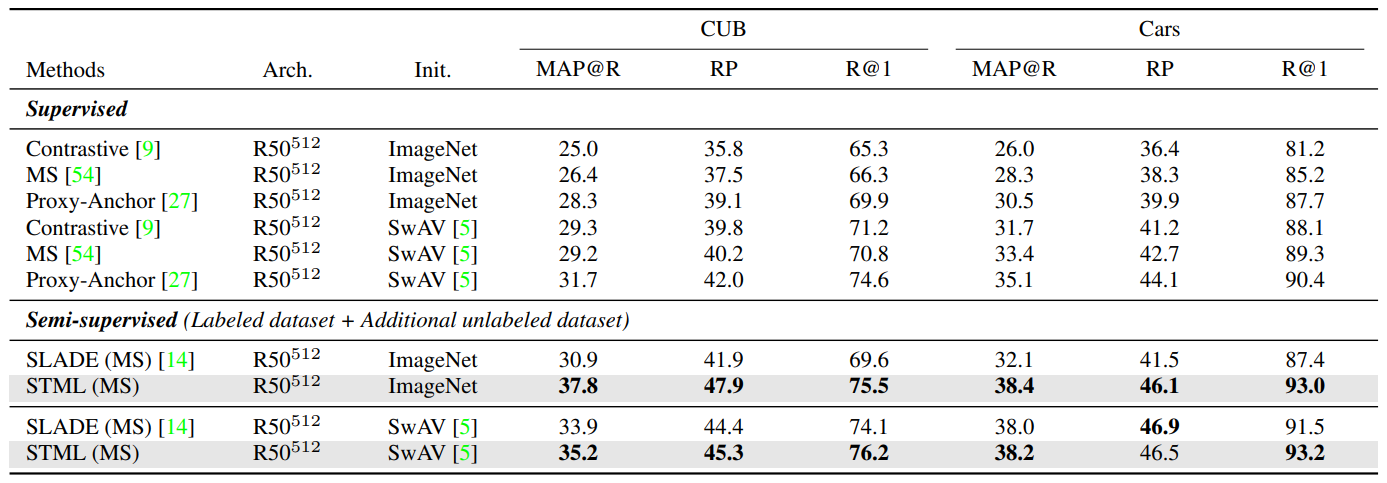
Overview of STML
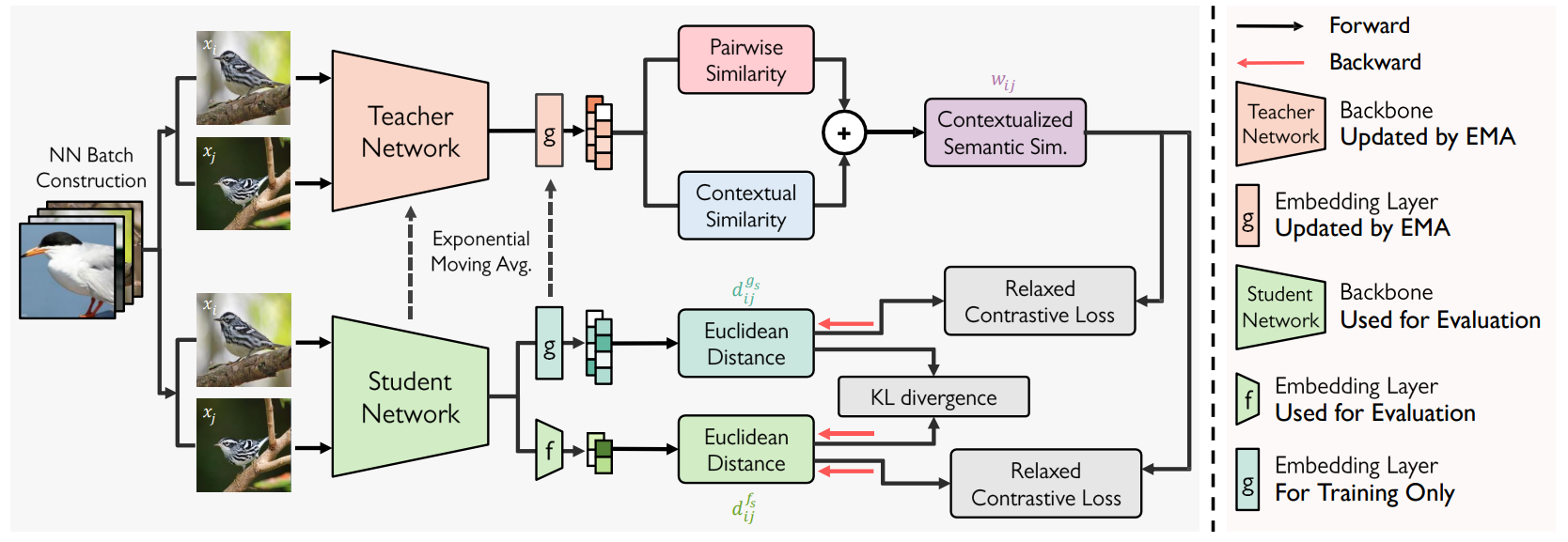
Figure 1. An overview of our STML framework. First, contextualized semantic similarity between a pair of data is estimated on the embedding space of the teacher network. The semantic similarity is then used as a pseudo label, and the student network is optimized by relaxed contrastive loss with KL divergence. Pink arrows represent backward gradient flows. Finally, the teacher network is updated by an exponential moving average of the student. The student network learns by iterating these steps a number of times, and its backbone and embedding layer in light green are considered as our final model.