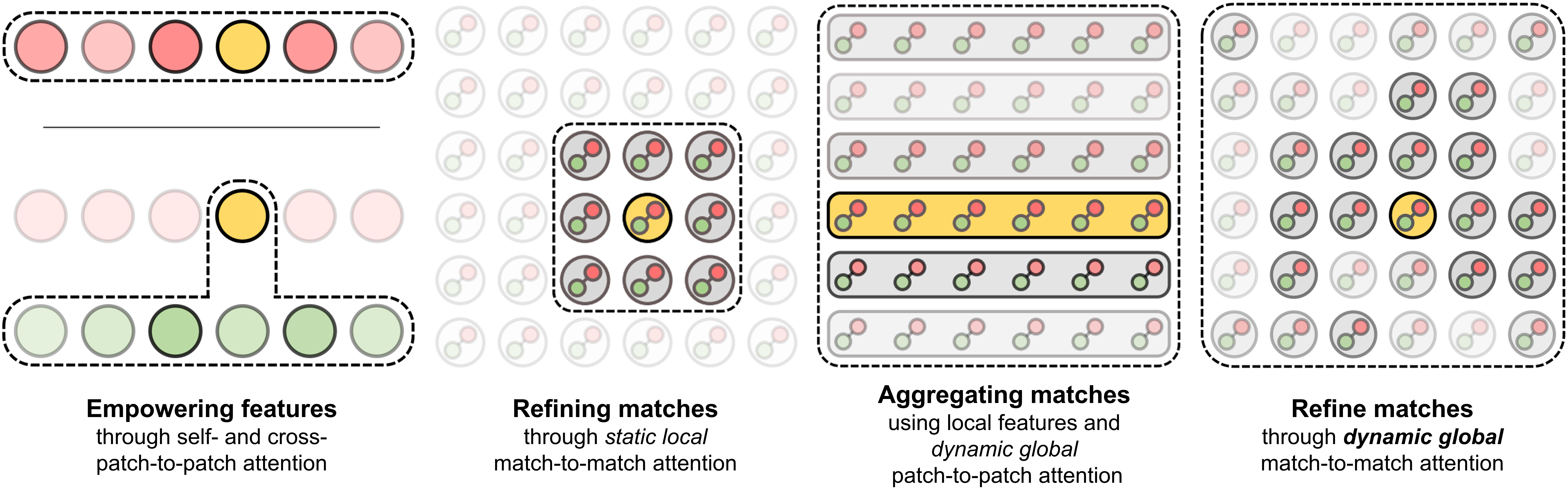
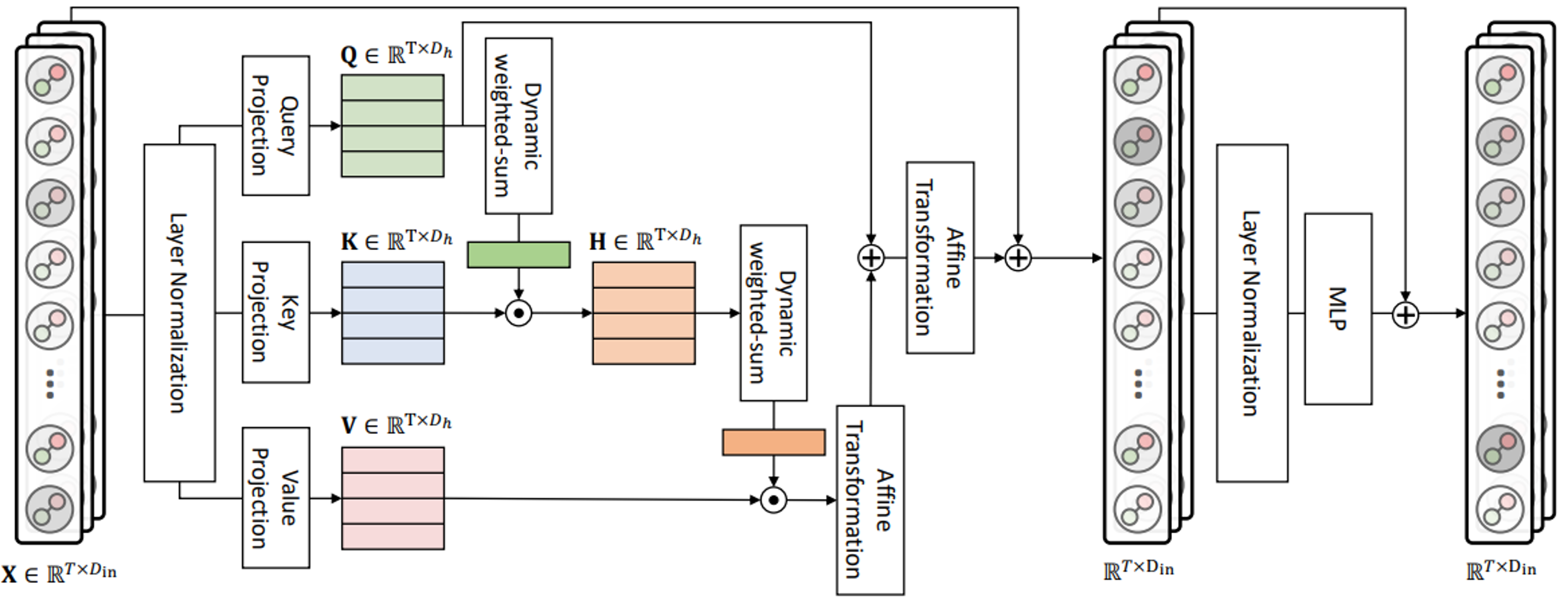
Overall pipeline of TransforMatcher.
Figure 1. The feature maps extracted from an image pair are used to compute a multi-channel correlation map to be processed by our match-to-match attention module for refinement. The multi-level scores are used as features for each match. We construct a dense flow field from the resulting correlation map, which can be used to transfer keypoints for training with keypoint pair annotation. We formulate our training objective to minimize the average Euclidean distance between the predicted target keypoints and the ground-truth target keypoints.