Abstract
Visual dialog is a task of answering a series of inter-dependent questions given an input image, and often requires to resolve visual references among the questions.
This problem is different from visual question answering (VQA), which relies on spatial attention (a.k.a. visual grounding) estimated from an image and question pair.
We propose a novel attention mechanism that exploits visual attentions in the past to resolve the current reference in the visual dialog scenario.
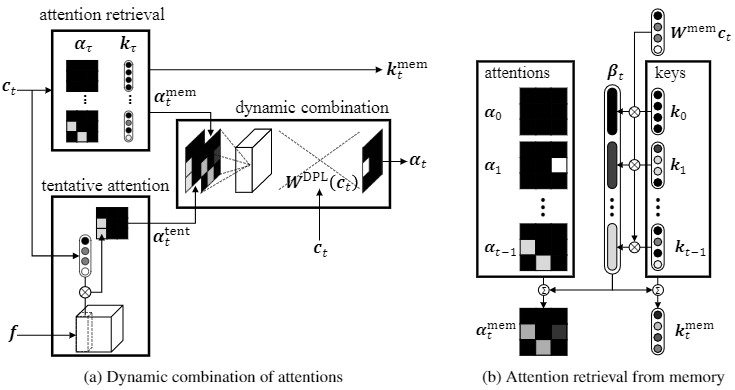
The proposed model is equipped with an associative attention memory storing a sequence of previous (attention, key) pairs.
From this memory, the model retrieves the previous attention, taking into account recency, which is most relevant for the current question, in order to resolve potentially ambiguous references.
The model then merges the retrieved attention with a tentative one to obtain the final attention for the current question; specifically, we use dynamic parameter prediction to combine the two attentions conditioned on the question.
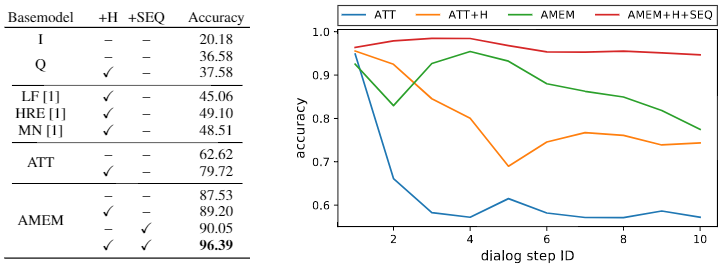
Through extensive experiments on a new synthetic visual dialog dataset, we show that our model significantly outperforms the state-of-the-art (by ~16 % points) in situations, where visual reference resolution plays an important role.
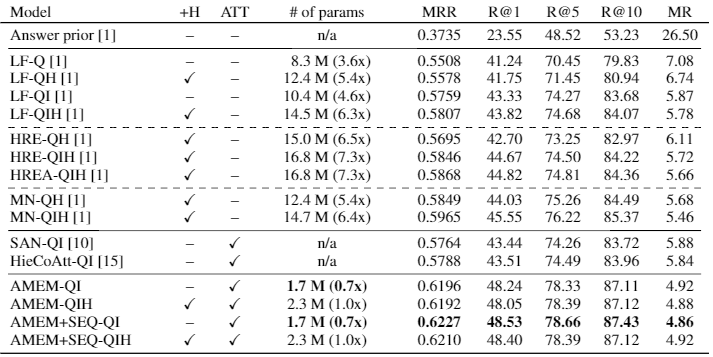
Moreover, the proposed model achieves superior performance (~ 2 % points improvement) in the Visual Dialog dataset, despite having significantly fewer parameters than the baselines.