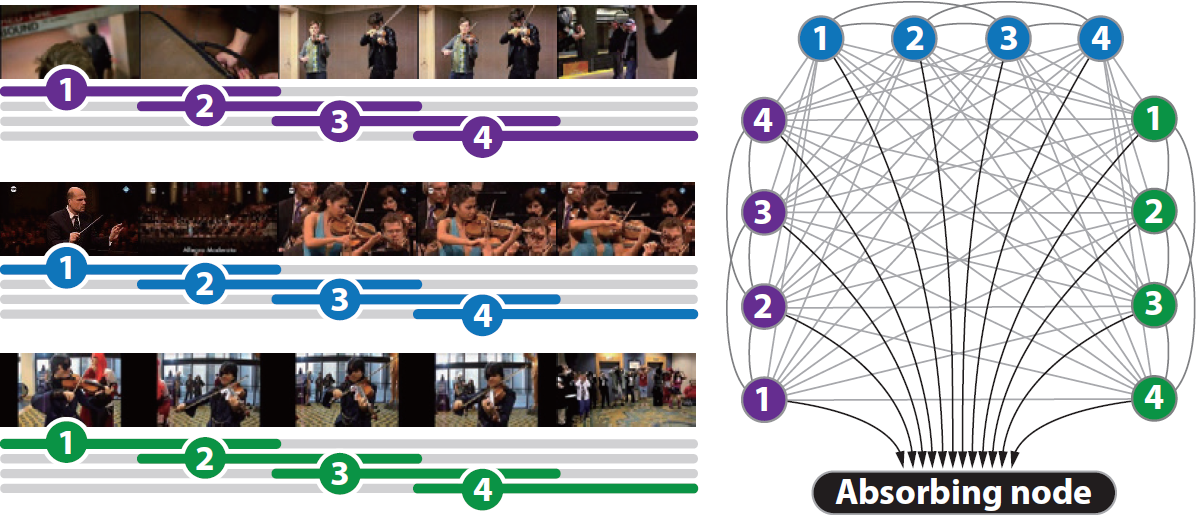
Figure 1. Visualization of the constructed graph for our absorbing Markov chain.
| Donghun Yeo | Bohyung Han | Joon Hee Han |
| POSTECH | ||
Figure 1. Visualization of the constructed graph for our absorbing Markov chain.
We propose a simple but effective unsupervised learning algorithm to detect a common activity (co-activity) from a set of videos, which is formulated using absorbing Markov chain in a principled way. In our algorithm, a complete multipartite graph is first constructed, where vertices correspond to subsequences extracted from videos using a temporal sliding window and edges connect between the vertices originated from different videos; the weight of an edge is proportional to the similarity between the features of two end vertices. Then, we extend the graph structure by adding edges between temporally overlapped subsequences in a video to handle variable-length co-activities using temporal locality, and create an absorbing vertex connected from all other nodes. The proposed algorithm identifies a subset of subsequences as co-activity by estimating absorption time in the constructed graph efficiently. The great advantage of our algorithm lies in the properties that it can handle more than two videos naturally and identify multiple instances of a co-activity with variable lengths in a video. Our algorithm is evaluated intensively in a challenging dataset and illustrates outstanding performance quantitatively and qualitatively. data through ensemble with the fully convolutional network.
YouTube co-activity dataset
Accuracy of individual co-activity classes in YouTube co-activity dataset.
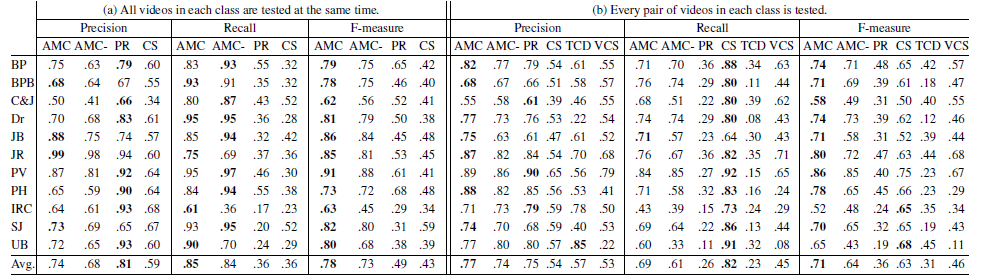
Additional datasets
The proposed algorithm is evaluated in three more datasets:
THUMOS14, Hollywood and UCF101 co-activity dataset. The first dataset
is THUMOS14 (Jiang et al.
2014), which is a large scale dataset for temporal action detection
and contains more than 200 temporally untrimmed
videos for 20 activity classes. This is a very challenging
dataset since the best known supervised action detection algorithm
achieves only 14.7% in mean average precision.
The second dataset is Hollywood (Laptev et al. 2008) which is orignially designed
for activity recognition and contains more than
400 temporally untrimmed videos for 8 classes of activity
videos. We generate another dataset, UCF101 co-activity
dataset, by concatenating temporally trimmed videos from
UCF101 (Soomro, Zamir, and Shah 2012). This dataset
consists of all 101 classes, each class contains 25 videos,
and each video is constructed from 4 trimmed videos and
has 2 co-activity instances. We exclude the results in these
dataset in the main paper since the annotations of Hollywood
dataset are noisy and the concatenated videos in UCF 101
co-activity videos are artificial.
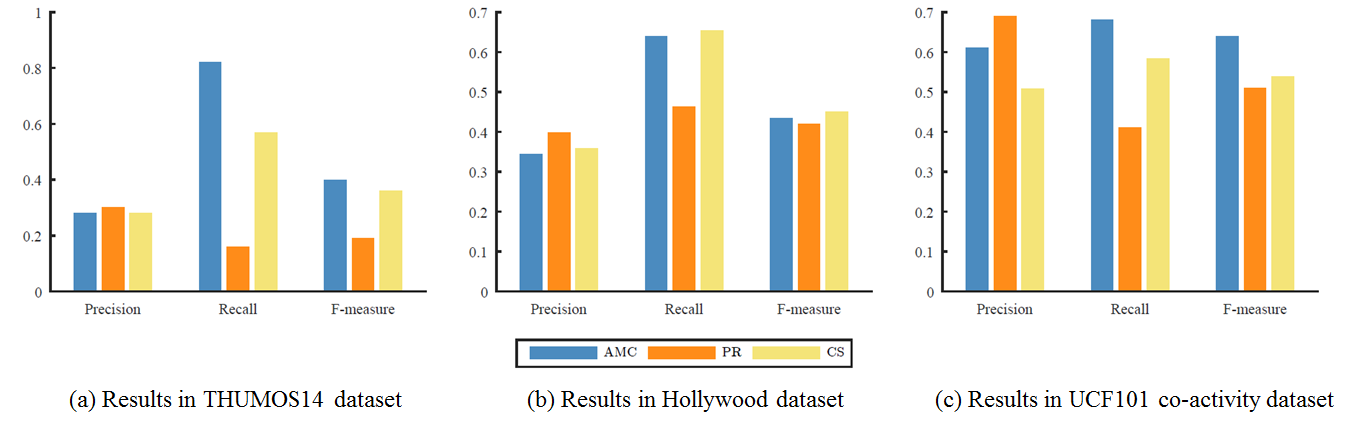
Figure 2. Quantitative co-activity detection results when all videos in each class are tested.
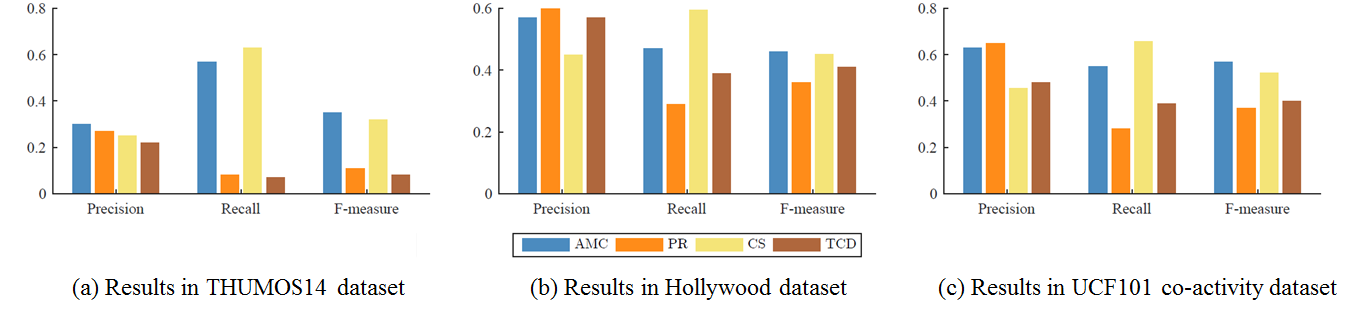
Figure 3. Quantitative co-activity detection results when every pair of videos in each class is tested.