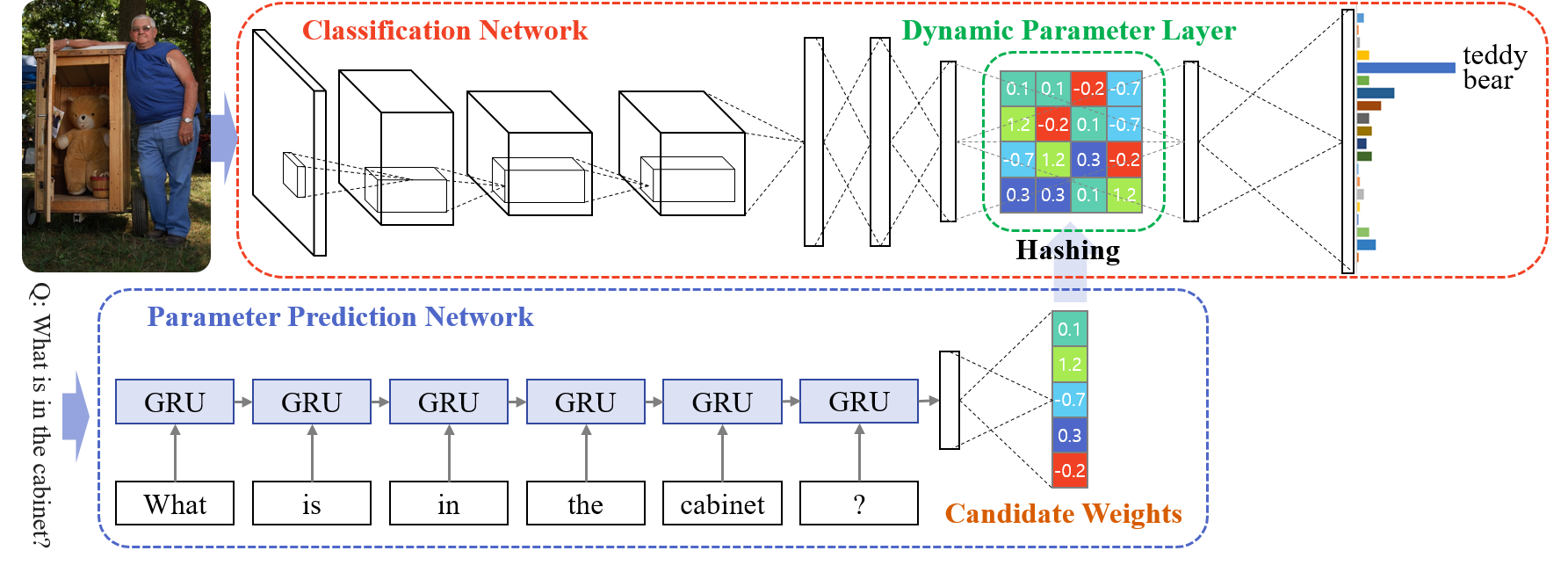
Overview
We tackle image question answering (ImageQA) problem by learning a convolutional neural network (CNN) with a dynamic parameter layer whose weights are determined adaptively based on a question.
For the adaptive parameter prediction, we employ a separate parameter prediction network, which consists of gated recurrent units (GRU) taking a question as its input and a fully-connected layer generating a set of candidate weights as its output.
Since the dynamic parameter layer is a fully connected layer, it is challenging to predict a large number of parameters in the layer to construct the CNN for ImageQA.
We reduce the complexity of this problem by incorporating a hashing technique, where the candidate weights given by the parameter prediction network are selected using a predefined hash function to determine individual weights in the dynamic parameter layer.
The proposed network---joint network with the CNN for ImageQA and the parameter prediction network---is trained end-to-end through back-propagation, where its weights are initialized using a pre-trained CNN and GRU.
The proposed algorithm illustrates the state-of-the-art performance on all available public ImageQA benchmarks.