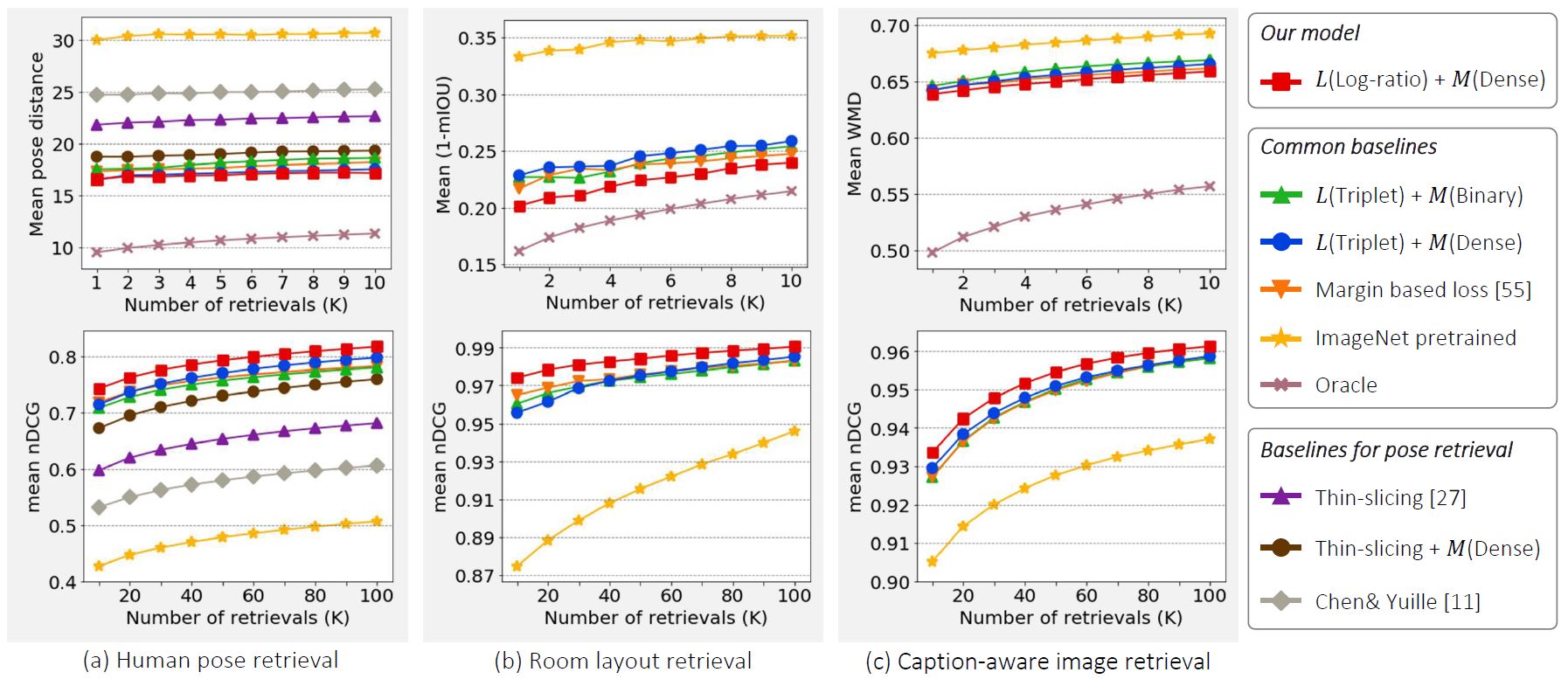
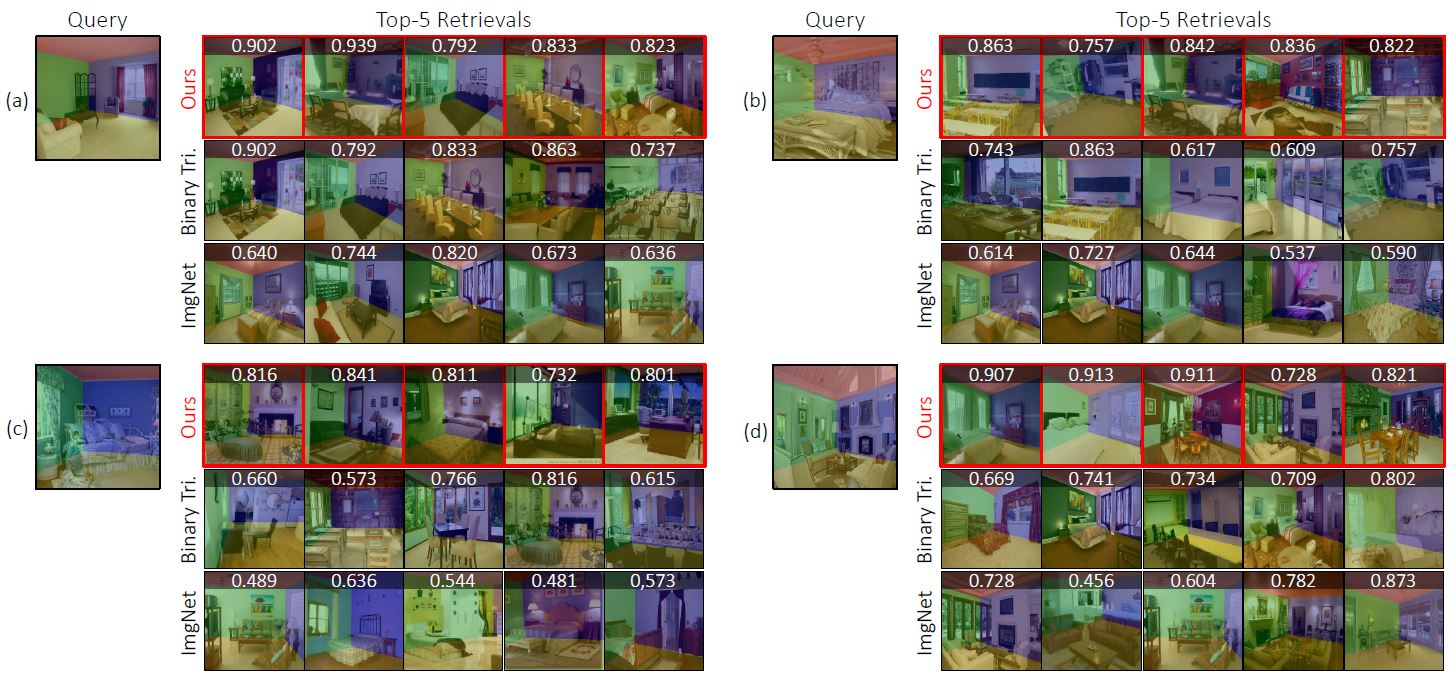
Our Framework vs Conventional Metric Learning
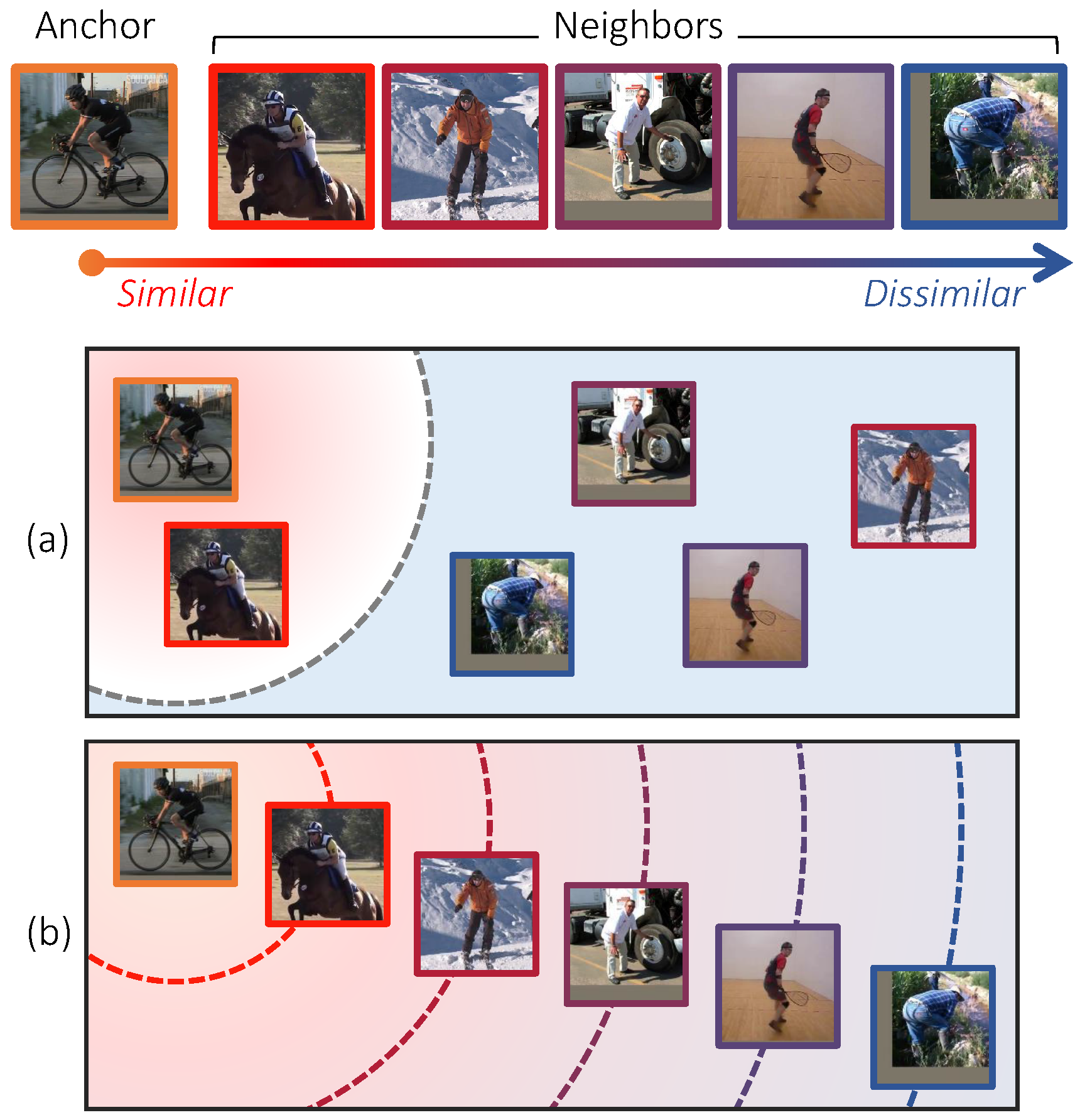
Figure 1. A conceptual illustration for comparing existing methods and ours. Each image is labeled by human pose, and colored in red if its pose similarity to the anchor is high. (a) Existing methods categorize neighbors into positive and negative classes, and learn a metric space where positive images are close to the anchor and negative ones far apart. In such a space, the distance between a pair of images is not necessarily related to their semantic similarity since the order and degrees of similarities between them are disregarded. (b) Our approach allows distance ratios in the label space to be preserved in the learned metric space so as to overcome the aforementioned limitation.