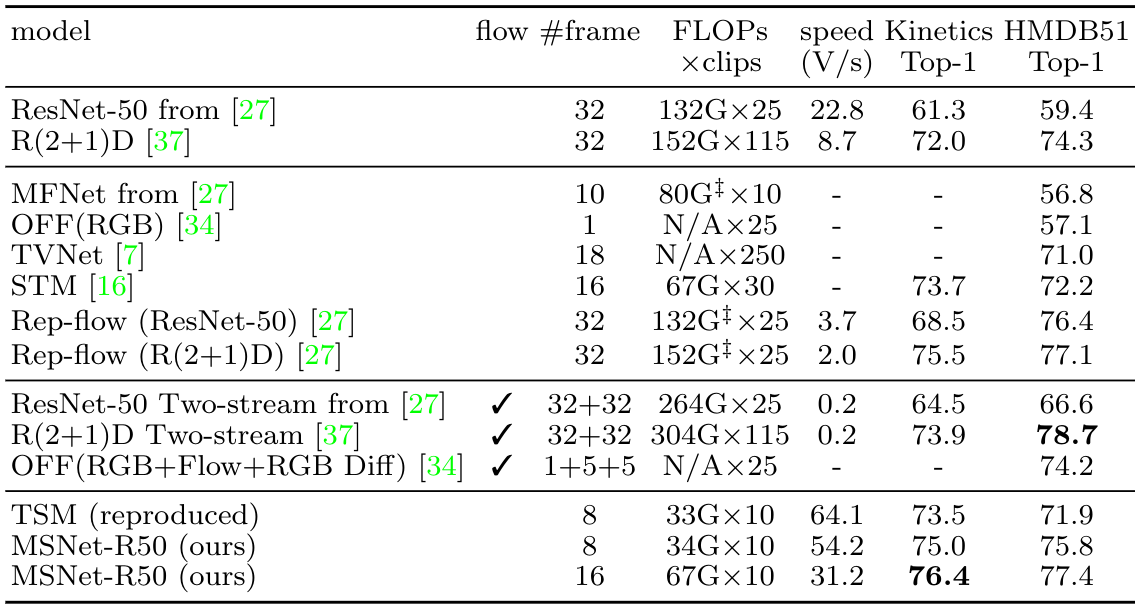
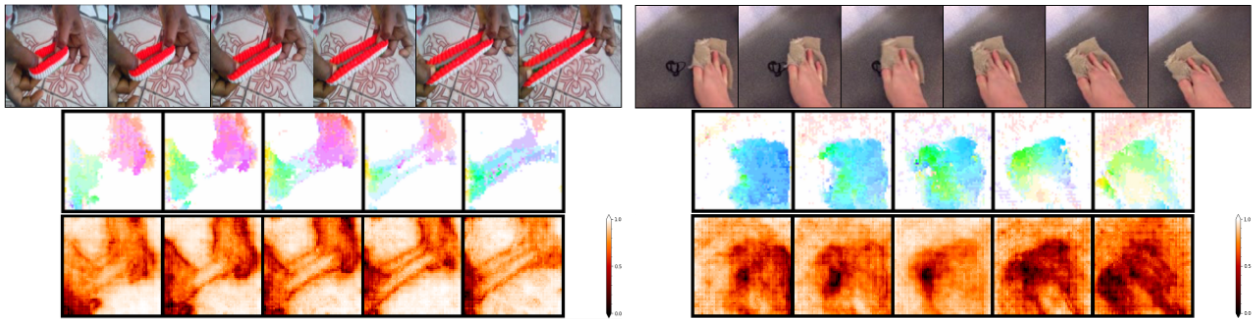
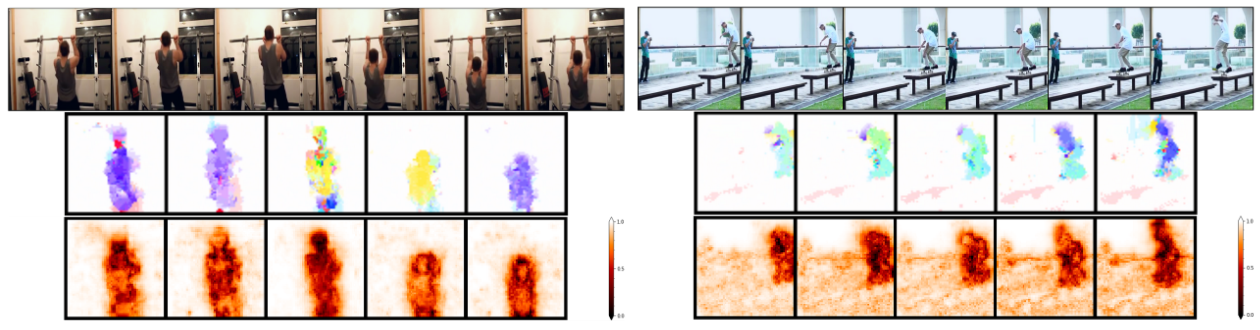
Abstract
Motion plays a crucial role in understanding videos and most state-of-the-art neural models for video classification incorporate motion information typically using optical flows extracted by a separate off-the-shelf method. As the frame-by-frame optical flows require heavy computation, incorporating motion information has remained a major computational bottleneck for video understanding. In this work, we replace external and heavy computation of optical flows with internal and light-weight learning of motion features.
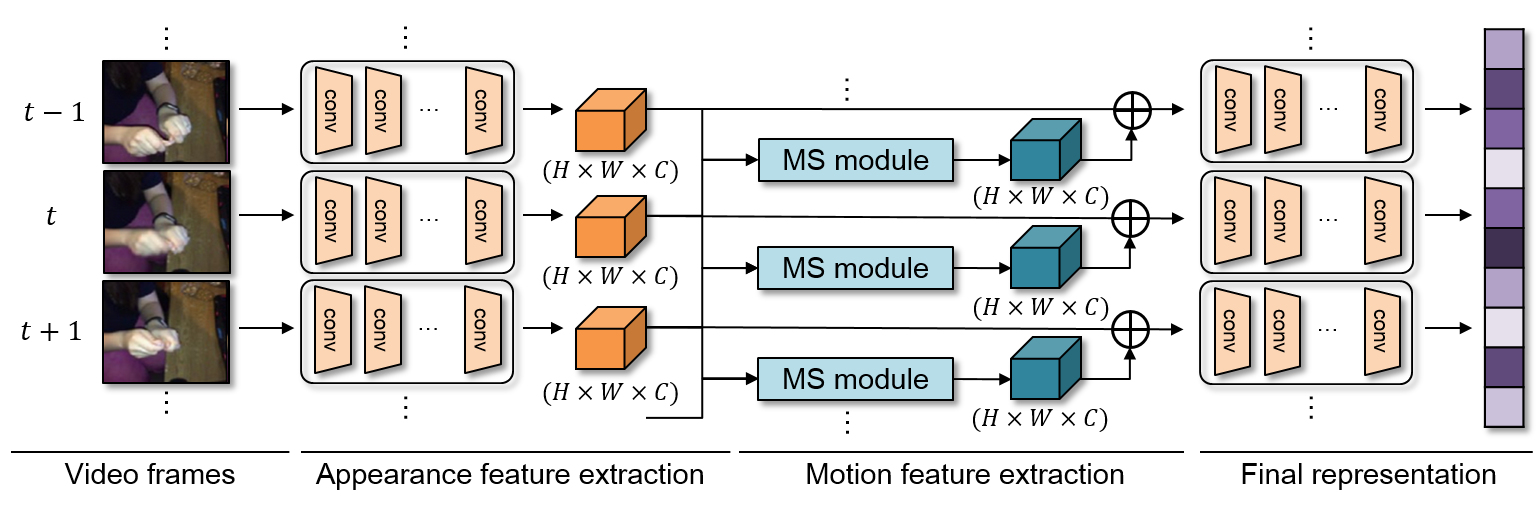
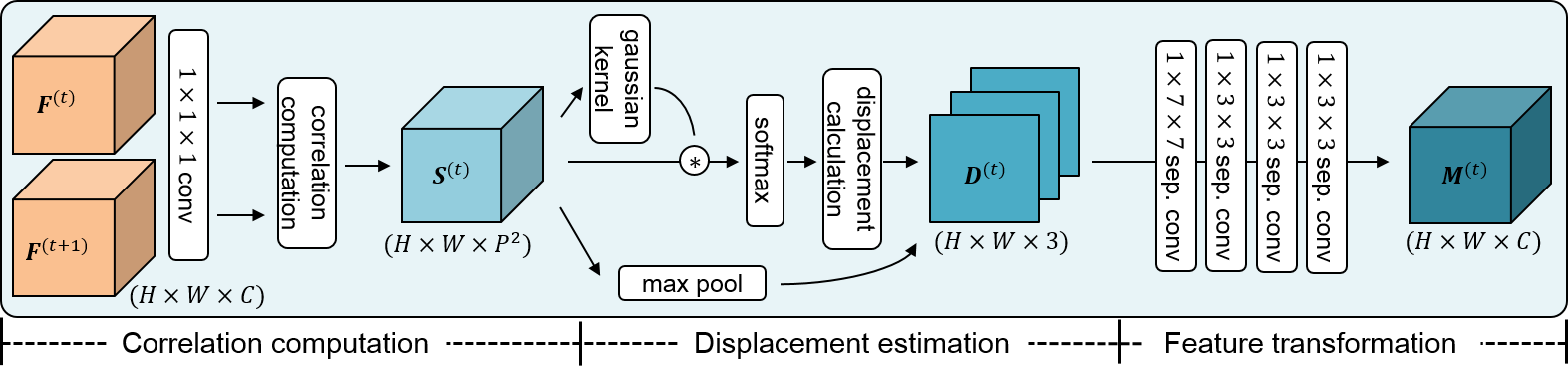
We propose a trainable neural module, dubbed MotionSqueeze, for effective motion feature extraction.
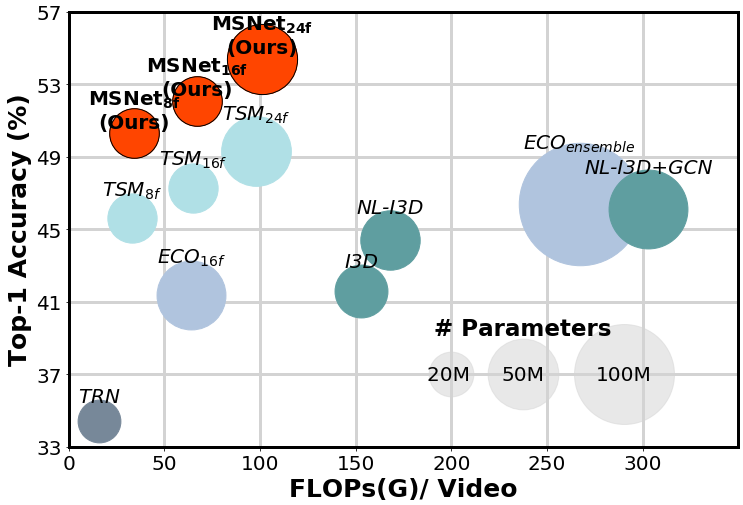
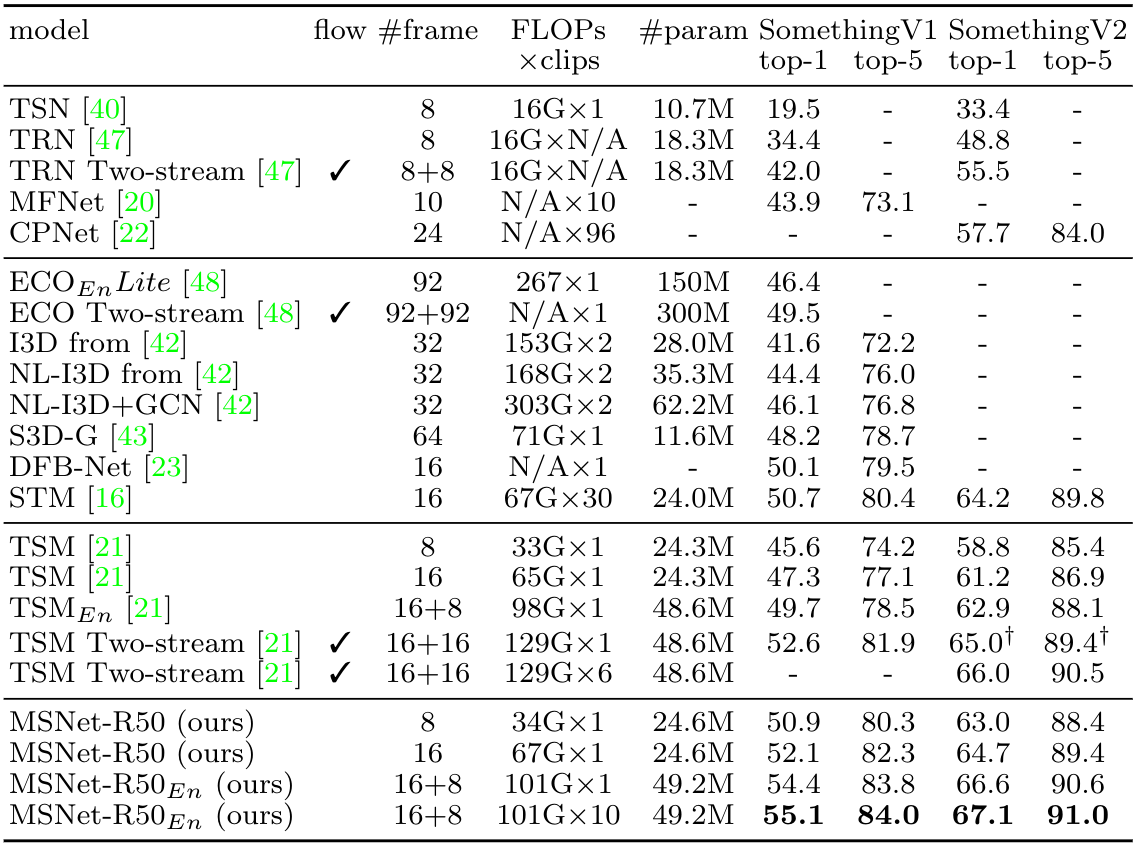
Inserted in the middle of any neural network, it learns to establish correspondences across frames and convert them into motion features, which are readily fed to the next downstream layer for better prediction. We demonstrate that the proposed method provides a significant gain on four standard benchmarks for action recognition with only a small amount of additional cost, outperforming the state of the art on Something-Something-V1&V2 datasets.