Dataset statistics and example pairs
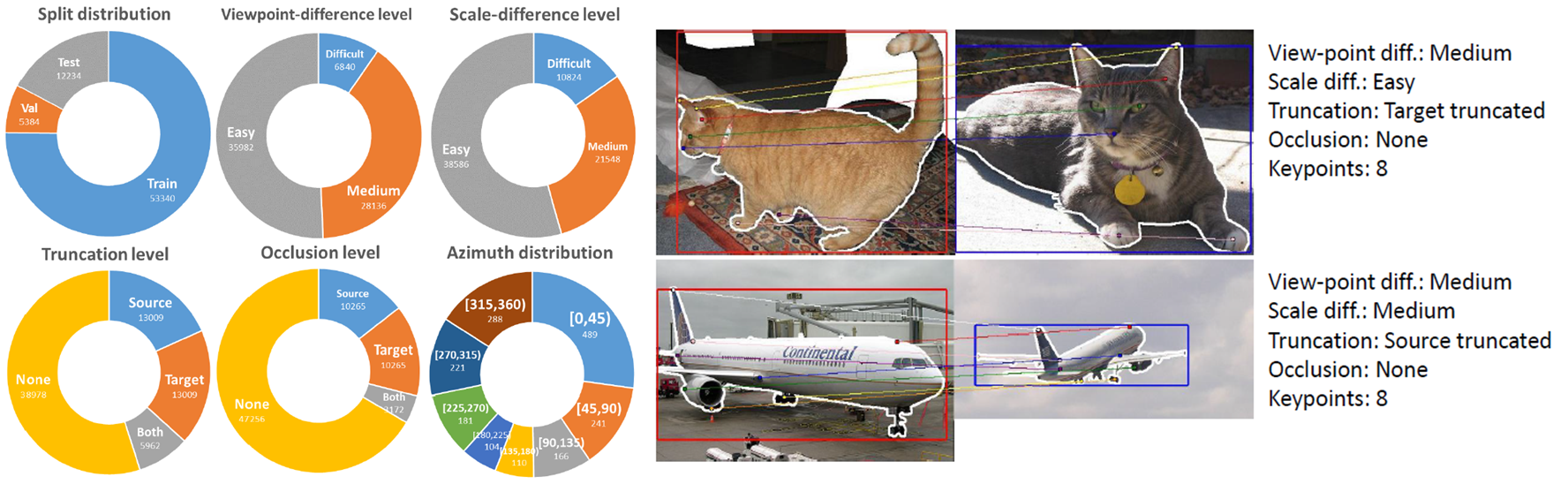
Figure 1. SPair-71k data statistics and example pairs with its annotations.

Table 2. Distribution of SPair-71k in terms of difficulty labels.
| Juhong Min1,2 | Jongmin Lee1,2 | Jean Ponce3,4 | Minsu Cho1,2 | ||||||||||||||||
| 1POSTECH | 2NPRC | 3Inria | 4DI ENS |
Establishing visual correspondences under large intra-class variations, which is often referred to as semantic correspondence or semantic matching, remains a challenging problem in computer vision. Despite its significance, however, most of the datasets for semantic correspondence are limited to a small amount of image pairs with similar viewpoints and scales. In this paper, we present a new large-scale benchmark dataset of semantically paired images, SPair-71k, which contains 70,958 image pairs with diverse variations in viewpoint and scale. Compared to previous datasets, it is significantly larger in number and contains more accurate and richer annotations. We believe this dataset will provide a reliable testbed to study the problem of semantic correspondence and will help to advance research in this area. We provide the results of recent methods on our new dataset as baselines for further research.
| Dataset name | Size (pairs) | Class | Source datasets | Annotations | Characteristics |
|---|---|---|---|---|---|
| Caltech-101 | 1,515 | 101 | Caltech-101 | object segmentation | tightly cropped images of objects, little background |
| PASCAL-PARTS | 3,884 | 20 | PASCAL-PARTS PASCAL3D+ |
keypoints (0~12), azimuth, elevation, cyclo-rotation, body part segmentation | tightly cropped images of objects, little background, part and 3D information |
| Animal-parts | ≈7,000 | 100 | ILSVRC 2012 | keypoints (1~6) | keypoints limited to eyes and feet of animals |
| CUB-200-2011 | 120k | 200 | CUB-200-2011 | 15 part locations, 312 binary attributes, bbox | tightly cropped images of object, only bird images |
| TSS | 400 | 9 | FG3DCar, JODS, PASCAL | object segmentation, flow, vectors | cropped images of objects, moderate background |
| PF-WILLOW | 900 | 5 | PASCAL VOC 2007, Caltech-256 | keypoints (10) | center-aligned images, pairs with the same viewpoint |
| PF-PASCAL | 1,300 | 20 | PASCAL VOC 2007 | keypoints (4~17), bbox | pairs with the same viewpoint |
| SPair-71k (ours) | 70,958 | 18 | PASCAL3D+, PASCAL VOC 2012 | keypoints (3~30), azimuth, viewpoint diff., scale diff., trunc. diff., occl. diff., object seg., bbox | large-scale data with diverse variations, rich annotations, clear dataset splits |
Tabel 1. Public benchmark datasets for semantic correspondence. The datasets are listed in chronological order.
Figure 1. SPair-71k data statistics and example pairs with its annotations.
Table 2. Distribution of SPair-71k in terms of difficulty labels.
SPair-71k dataset contains 7 subdirectories in its root directory. Contents of each subdirectory are
If the dataset is used for your research, please cite our ICCV paper [bibtex] and/or dataset article [bibtex].

Table 3. Per-class PCK results on SPair-71k dataset. For the authors' original models, the models of [9, 12] trained on PASCAL-VOC with self-supervision, [10, 11] trained on PF-PASCAL with weak-supervision, and [8] tuned using validation split of SPair-71k are used for evaluation. For SPair-71k-fintuned models, the original models are further finetuned on SPair-71k dataset by ourselves with our best efforts. Numbers in bold indicate the best performance and underlined ones are the second and third best.

Table 4. PCK analysis by variation factors on SPair-71k. The variation factors include view-point, scale, truncation, and occlusion.
The SPair-71k data includes images and metadata obtained from the PASCAL-VOC and flickr website. Use of these images and metadata must respect the corresponding terms of use.
[SPair-71k.tar.gz] (230.8 MB)
Update (2021-07-08): We corrected partly-misannotated bounding boxes in 29 pairs in test split (out of 12,234 pairs). We thank Anselm Paulus for reporting the annotation errors. Note that the impact of these misannotated boxes in PCK evaluation is negligible as they amount to 0.002% of whole test pairs.